International Developers in London Conference
El pasado sábado asistí a la “International Developers in London Conference”. Esta conferencia forma parte de los diferentes eventos englobados en los meetups International Developers in London (valga la redundancia), organizados por un recruiter llamado Adam Bolton. Los recruiters de esta ciudad no son conocidos precisamente por su profesionalidad y buenas formas, pero este en cuestión entraría dentro de la categoría de “buenos recruiters”.
Cuando digo “en los meetups”, es porque se trata realmente de diferentes grupos enfocados a desarrolladores que tienen en común dos cosas, ser extranjeros en UK, y su país de origen (sea Italia, Francia, España, etc). Se trata de una iniciativa bastante interesante, porque propone realizar presentaciones ante personas que no son nativos, por lo que el factor vergüenza al tener que utilizar una segunda lengua disminuye considerablemente. De hecho, no descarto proponer una charla algún día, cuando considere que tengo algo realmente interesante que contar.
La conferencia no giró en torno a tecnologías en concreto, como sí pueda ocurrir con otras a las que he asistido, pero siempre se pueden sacar lecciones de provecho. Resumiré en este post lo que me pareció más interesante, y que puede que me resulte de utilidad en un futuro más o menos cercano.
High performance web platform (Martin Beeby)
Con la implantación definitiva de dispositivos móviles, la denominada como experiencia de usuario resulta cada vez más importante, y aquí es donde estamos los programadores para optimizar el rendimiento de las aplicaciones Web.
Me resultó muy interesante la diferenciación entre “Performance” y “Perceived Performance” / “Time to Glass”. Pido disculpas por la no traducción de determinados conceptos, pero considero que castellanizar algunas expresiones en informática sencillamente carece de sentido (léase TDD vs Diseño dirigido por tests). Diríamos que time to glass es el tiempo que tarda el usuario en ver la pantalla que espera, lo cual no significa que todos los recursos estén cargados. Podemos encontrarnos que este tiempo es inferior en un factor 3X o 4X del tiempo real de carga de todos los recursos, y es necesario minimizarlo al máximo. ¿Tiene sentido, verdad? Creo que a todos nos resulta muy molesto estar esperando con la pantalla en blanco a ver algo cuando introducimos una URL en nuestro navegador.
Por otro lado, es importante no perder de vista el consumo de batería si queremos enfocar nuestras webs a dispositivos móviles. Sobre este asunto se habló de la importancia de priorizar “Target Devices”, mediante herramientas como Google Analytics.
Otas consideraciones importantes en lo referente al rendimiento web son:
- Minimizar el tamaño de las imágenes. No interesa alojar png’s de la máxima calidad cuando luego serán reprocesados en el cliente. Conviene priorizar además el formato jpg sobre el png
- Usar Image Sprites para cargar conjuntos de iconos, en lugar de iconos individuales. Así reducimos drásticamente las peticiones HTTP gracias a la caché de los navegadores
- Alojar los recursos en Content Delivery Networks (CDN). Personalmente fue la primera vez que escuché hablar de estos sistemas, pero por lo visto en la presentación la mejora es sustancial
- Incluir los ficheros Javascript al final de nuestras páginas HTML, para posponer su carga. Esto está muy relacionado con el “time to glass” comentado previamente
- Minimizar los ficheros Javascript y CSS en las versiones de producción
- Reducir el número de frameworks utilizados en el Front-End. Queda muy bien listar 10 frameworks diferentes para estar a la última (jQuery + jQuery UI + Bootstrap, + AngularJS +…), pero prestad atención a la siguiente comparativa mostrada en la presentación (cortesía de Martin Beeby)
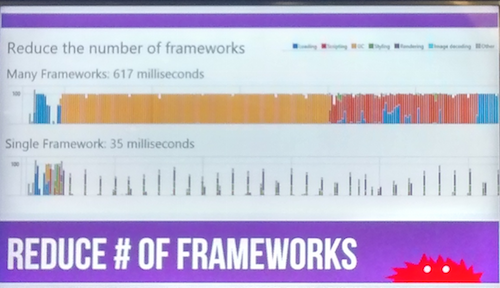
Por último aquí van una serie de recursos web interesantes para mejorar el rendimiento de nuestras aplicaciones web:
- http://webdevchecklist.com/: Checklist para desarrollo web
- Yahoo YSlow: analiza posibles causas de un bajo rendimiento
- Google PageSpeed Insights: herramienta similar, esta de Google
Para finalizar con el resumen de esta charla un dato: un descenso en la latencia de 100ms le supone a Amazon una pérdida en ventas del 1%, equivalente a 2.000.000$ AL DÍA. UX matters, que diría aquel.
Escalabilidad
Hubo dos charlas interesantes al respecto, “Designing distributed, scalable and reliable systems” por Mauro Servienti, y “Just queue it!” por Marcos Placona. La escalabilidad es un tema muy recurrente en los últimos tiempos, y parecer ser que todos los sistemas deben diseñarse para ser lo más escalable posible, pero expertos en el tema dejaron claro que a veces “las hojas no te dejan ver el bosque”. Veamos por qué.
Pensemos en una aplicación que recibe al día 25.000 visitantes, y cada uno de ellos consulta una media de 6 páginas. Además sabemos que estas visitas se distribuyen de forma más o menos uniforme a lo largo de 11 horas. Esta cifra nos podría hacer pensar en escalar el sistema a lo ancho (Scale out), es decir, añadiendo nodos/servidores, en lugar de añadir recursos a nuestro único servidor (Scale up). Pero, ¿son estas cifras tan elevadas? Veamos:
- 25.000 * 6 = 150.000 páginas/día
- 150.000 / 11 = 13.636 páginas/hora
- 13.636 / 60 = 227 páginas/minuto
- 227 / 60 = 3.7 páginas/segundo
La conclusión es que si nuestra aplicación tiene problemas para servir 4 páginas por segundo es que tenemos un problema (escalabilidad aparte), y deberíamos intentar buscar cuellos de botella (bottlenecks) que puedan estar causando incidencias. Si las visitas aumentan, pero no de forma drástica, en primera instancia siempre será más sencillo añadir recursos que pensar en escalar a lo ancho (Scaling out).
Una vez nos encontremos con que ya es inevitable pensar en soluciones distribuidas, debemos olvidarnos de la típica arquitectura “Request/Response”, que en este tipo de arquitecturas está considera un anti-pattern, y orientarnos más bien a un diseño Publish-subscribe. Este patrón de diseño es a grandes rasgos una evolución del patrón Observer, en el que los sistemas implicados están totalmente desacoplados mediante el uso de colas de mensajes (Queues).
Las tecnologías que gestionan colas de mensajes son variadas. Algunas de ellas requieren que todos los sistemas implicados compartan infraestructura (por ejemplo, ActiveMQ nos obliga a que todas las partes estén desarrolladas en Java, o al menos corran sobre la JVM), mientras que otros no imponen obligaciones en este aspecto y pueden estar más recomendados cuando desconocemos cuales serán los ecosistemas involucrados a priori (en este grupo tenemos RabbitMQ o IronMQ).
Personalmente he trabajado durante los últimos diez meses en un sistema con esta filosofía (concretemente en un ecosistema JBoss Fuse, que utiliza ActiveMQ o Apache Camel entre otros), por lo que es más que seguro que volveré a hablar de todo esto más adelante.
Otras charlas
Se hablaron de otras cosas, como la importancia de seleccionar las palabras claves para aplicaciones subidas a la App Store de Apple a la hora de ganar visibilidad, las virguerías que se pueden hacer con Arduino, la plataforma Native Script, para desarrollo Cross platform de aplicaciones móviles, o una introducción a la metodología SCRUM.
Fue un día bastante provechoso, y repetiría sin dudarlo, máxime cuando además no me fui con las manos vacías, ¡me tocó una de las rifas! :) Aquí la foto que da fe de ello:
