El patrón Composite en la práctica
Los patrones de diseño del Gang of Four son una de las piedras angulares en el desarrollo de software. Algunos de ellos tan importantes que han sido absorbidos por implementaciones nativas en los lenguajes de programación y los damos como algo dado sin darnos cuenta del patrón que reside detrás (caso de Iterator).
Para aprender el funcionamiento de estos patrones se suele remitir al libro original, aunque en mi caso los aprendí con el magnífico Head First Design Patterns. Internet está lleno de referencias y explicaciones, por supuesto, y yo aportaré mi granito de arena con ejemplos prácticos de uso de algunos de ellos.
Composite
Este patrón es, a mi parecer, uno de los más útiles para conseguir un código dividido en pequeñas piezas reusables y testeables, que respetan al máximo el Single Responsibility Principle. Esto significa que una vez tenemos desarrollada cierta funcionalidad dentro de una clase, en pocas ocasiones tendremos un motivo para cambiar dicha clase en el futuro. Lo veremos más claro con el ejemplo.
La definición “oficial” del patrón la podemos encontrar en Wikipedia, traducido sería:
En Ingeniería del Software, el patrón Composite es un patrón de diseño utilizado para particionar. El patrón Composite describe un grupo de objetos que serán tratados de la misma forma como una instancia única de un objeto. La intención del patrón es “componer” objetos en estructuras de árboles para representar jerarquías. Implementar el patrón Composite permite a los clientes tratar objetos individuales y composiciones uniformemente.
Y el diagrama UML (en el mismo sitio) es:
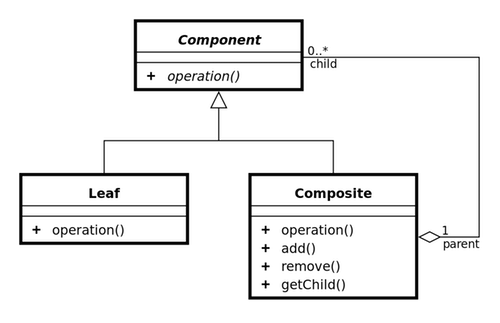
Por tanto tenemos que:
- Existe una interfaz
Componentque define una operación - Dicha interfaz es implementada por dos clases,
LeafyComposite - La clase
Leafcontiene una implementación específica de la operación - La clase
Compositecontiene un número variable de referencias (children) a instancias de la interfazComponent. Dichas instancias pueden serLeafo, de nuevoComposite, permitiendo generar las estructuras en forma de árbol que se mencionan en la definición - La implementación de la operación en
Compositedelegará en la operación de cada una de las instancias “child” - Las instancias de
Compositeestán “vivas”, es decir, mediante sus operacionesaddyremovepermiten configurar la jerarquía que contiene
Es este último punto precisamente el que supone un pequeño hándicap para este patrón de diseño. En el libro de la serie “Head First” se discute bastante sobre este asunto, el problema es que estas operaciones al ser específicas de la clase Composite no pertenecen a la interfaz, por lo que, en cierta medida, los clientes han de ser conscientes de las implementaciones que existen de la interfaz (y hacer downcasting), rompiendo el principio Program to an interface, not an implementation. Otra posible solución sería elevar las operaciones a la interfaz, y lanzando una excepción si las invocamos desde Leaf, pero esa solución me parece igualmente mala.
La versión inmutable
En general, el típico ejemplo para explicar el patrón Composite es una aplicación de dibujo en la que a partir de formas geométricas básicas (círculo, cuadrado…) creamos formas más complejas que se van agrupando. En este caso sí que tiene sentido el carácter vivo de la clase Composite.
Sin embargo, el mayor uso que yo he ido encontrando para este patrón es bastante diferente, y guarda relación con lo que mencionaba al principio de este artículo. Cuando nos enfrentamos al desarrollo de aplicaciones de gran dimensión, es muy frecuente que determinadas clases que tienen como objetivo realizar tareas repetitivas en pasos sucesivos vayan creciendo y creciendo debido a nuevos requerimientos.
Lo que ocurre a largo plazo es que un determinado módulo o clase se vuelve inmanejable, y cada vez más difícil de testear. La consecuencia más directa suele ser que se dejan de mantener los tests, lo cual es terrible, y la segunda consecuencia es que cada vez es más difícil de mantener.
En gran medida, estos problemas pueden evitarse con lo que yo llamo la versión inmutable del patrón Composite. Es inmutable porque se inicializa una sola vez y no permite modificar su estrucutra, es decir, nos cargamos las operaciones add y remove de la versión vista más arriba. Veámoslo con un ejemplo concreto.
Una implementación de ejemplo
Imaginemos un escenario en el que tenemos que validar una estructura de datos utilizada para dar de alta un nuevo usuario en un sistema.
public class NewUserInfo {
private String name;
private String surname;
private Address address;
private int age;
private String password;
//...
}
public class Address {
private String line1;
private String line2;
private String county;
private String city;
private String postcode;
//...
}Los datos pueden provenir de un servicio web, un formulario HTML…no es demasiado importante para el ejemplo.
Lo que queremos es crear un clase Validator que reciba la instancia de NewUserInfo y devuelva una lista de Strings con todos los errores encontrados (campos sin rellenar, password insegura, menor de edad…). Es decir, queremos esto:
public interface Validator<T> {
List<String> validate(T info);
}La interfaz es genérica, ya que así podríamos reutilizarla para otras estrucuturas de datos.
Sin el patrón Composite, lo normal sería crear una implementación, NewUserInfoValidator, que fuera validando de forma sucesiva todos y cada uno de los campos, con la complejidad añadida de que cada campo requiere de validaciones diferentes. Por mucho que intentemos seguir las prácticas de Clean Code, lo más normal es que esa clase crezca a varios cientos de líneas, y que además requiera de mantenimiento posterior cada vez que necesitemos añadir un nuevo campo a la estructura de datos o una nueva validación a uno de los campos existentes. Por no hablar de lo monstruosos que pueden llegar a ser los tests.
Vamos, por tanto, a utilizar el patrón Composite para separar la validación en piezas, a partir del siguiente diagrama UML:
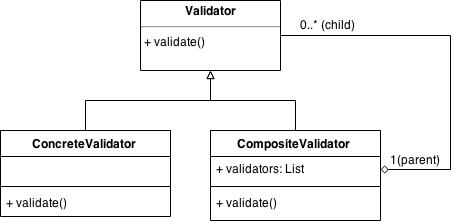
La clase CompositeValidator
La implementación de la clase Composite sería:
public class CompositeValidator<T> implements Validator<T> {
private final List<Validator<T>> validators;
public CompositeValidator(List<Validator<T>> validators) {
this.validators = validators;
}
@Override
public List<String> validate(T info) {
List<String> errors = Lists.newArrayList();
for (Validator validator : validators) {
errors.addAll(validator.validate(info));
}
return errors;
}
}Como vemos, no hace más que delegar la validación a cada uno de sus “hijos” y recopilar los resultados. Lo bueno de esta estructura, es que ¡los hijos pueden ser tanto implementaciones concretas como nuevos Composites!
Las implementaciones “concretas”
La idea es dividir las validaciones de los diferentes campos (o grupos de campos asociados) en sus propias clases Validator. Veamos un par de ejemplos:
public class NameValidator implements Validator<NewUserInfo> {
@Override
public List<String> validate(NewUserInfo info) {
List<String> errors = Lists.newArrayList();
String name = info.getName();
String surname = info.getSurname();
if (StringUtils.isEmpty(name)) {
errors.add("Name must be populated");
}
if (StringUtils.isEmpty(surname)) {
errors.add("Surname must be populated");
}
return errors;
}
}
public class AgeValidator implements Validator<NewUserInfo> {
@Override
public List<String> validate(NewUserInfo info) {
List<String> errors = Lists.newArrayList();
int age = info.getAge();
if (age < 18) {
errors.add("Age must be >= 18");
}
return errors;
}
}(El resto de clases Validator están en el código subido a GitHub)
Creo que queda bastante claro de qué forma se simplifica el código en pequeñas piezas reutilizables. Un posible temor ante esta situación es encontrarnos ante un montón de clases por mantener, pero yo diría que es mucho más fácil mantener pequeñas clases fáciles de entender y localizar que una clase gigantesca en la que hay que bucear para encontrar el código a modificar. Y por último reducimos los potenciales motivos para modificar una clase determinada.
¿Cuántas veces en el futuro creéis que será necesario modificar la clase AgeValidator o CompositeValidator? Diría que el cambio es altamente improbable. Por otro lado, si un nuevo campo es añadido a la estructura de datos, lo único que deberíamos hacer sería crear una nueva clase para validar ese nuevo campo y agregarla a la jerarquía.
Juntando las piezas
La agregación de las diferentes piezas la haremos en el fichero XML para configurar el contexto de Spring. De esta forma podemos establecer la configuración de nuestro validador sin tocar para nada las clases.
<bean id="newUserInfoValidator"
class="com.raulavila.patterns.composite.CompositeValidator">
<constructor-arg>
<list>
<ref bean="nameAndAddressValidator" />
<ref bean="ageValidator" />
<ref bean="passwordValidator" />
</list>
</constructor-arg>
</bean>
<bean id="nameAndAddressValidator"
class="com.raulavila.patterns.composite.CompositeValidator">
<constructor-arg>
<list>
<ref bean="nameValidator" />
<ref bean="addressValidator" />
</list>
</constructor-arg>
</bean>
<bean id="nameValidator"
class="com.raulavila.patterns.composite.NameValidator"/>
<bean id="addressValidator"
class="com.raulavila.patterns.composite.AddressValidator"/>
<bean id="ageValidator"
class="com.raulavila.patterns.composite.AgeValidator"/>
<bean id="passwordValidator"
class="com.raulavila.patterns.composite.PasswordValidator"/>Es un poco forzado el segundo nivel creado con nameAndAddressValidator, que he añadido a efectos de demostración. En proyectos más reales se utilizarían los diferentes niveles en la jerarquía para agrupar validaciones de campos relacionados, o agrupar diferentes tipos de validaciones en el mismo campo (por ejemplo, separar una validación básica con otra más compleja que necesitara comunicarse con un sistema externo, por ejemplo).
Veamos un ejemplo del funcionamiento de nuestro validador:
ApplicationContext context = new ClassPathXmlApplicationContext(
"spring-beans-composite.xml");
@SuppressWarnings("unchecked")
Validator<NewUserInfo> newInfoUserValidator =
context.getBean("newUserInfoValidator", Validator.class);
NewUserInfo newUserInfo = new NewUserInfo();
List<String> errors = newInfoUserValidator.validate(newUserInfo);
System.out.println(errors);La salida de esta pequeña aplicación, dado que estamos validando una instancia sin rellenar (por lo que contiene los valores por defecto) sería una lista con los siguientes mensajes:
"Name must be populated",
"Surname must be populated",
"Address can't be null",
"Age must be >= 18", //age contiene el valor por defecto para int => 0
"Password field must be populated"Los tests
Veamos por último lo sencillos que quedarían algunos de los tests. Empecemos con el test de la clase CompositeValidator:
public class CompositeValidatorTest {
private CompositeValidator<Object> compositeValidator;
@Mock
private Validator<Object> validator1;
@Mock
private Validator<Object> validator2;
@Mock
private Object info;
@Before
public void setUp() throws Exception {
MockitoAnnotations.initMocks(this);
List<Validator<Object>> validators =
Lists.newArrayList(validator1, validator2);
compositeValidator = new CompositeValidator<Object>(validators);
when(validator1.validate(info)).thenReturn(Lists.newArrayList("error1"));
when(validator2.validate(info)).thenReturn(Lists.newArrayList("error2"));
}
@Test
public void testComposite() throws Exception {
List<String> errors = compositeValidator.validate(info);
verify(validator1).validate(info);
verify(validator2).validate(info);
assertThat(errors).containsExactly("error1", "error2");
}
}Se comprueba que la clase Composite delega en sus hijos, como es de esperar.
Cada una de las clases Validator en particular tendría su propia clase específica de test, en el caso de AgeValidator sería algo como:
public class AgeValidatorTest {
private AgeValidator ageValidator = new AgeValidator();
@Mock
private NewUserInfo newUserInfo;
@Before
public void setUp() throws Exception {
MockitoAnnotations.initMocks(this);
}
@Test
public void testAdult() throws Exception {
when(newUserInfo.getAge()).thenReturn(20);
List<String> errors = ageValidator.validate(newUserInfo);
assertThat(errors).isEmpty();
}
@Test
public void testChild() throws Exception {
when(newUserInfo.getAge()).thenReturn(15);
List<String> errors = ageValidator.validate(newUserInfo);
assertThat(errors).hasSize(1);
assertThat(errors).contains("Age must be >= 18");
}
}Imaginad cuál sería el aspecto de los tests si una sola clase fuera la encargada de validar todos y cada uno de los campos :)
Con esto termino mi repaso a este enfoque inmutable del patrón Composite, que yo personalmente he encontrado de extrema utilidad para varios proyectos en los que he trabajado.