Optimizando el patrón Producer-Consumer con TransferQueue
El multithreading es quizás el área más peliaguda del desarrollo software. No es mi intención en este post desgranar todos los problemas que nos podemos encontrar al diseñar e implementar un sistema con máxima concurrencia, pero seguramente os suenen conceptos como deadlocks, liveness, etc, que son increíblemente difíciles de depurar debido al indeterminismo de este tipo de aplicaciones.
Como en cualquier ámbito de ingeniería, el uso de patrones facilita enormemente el desarrollo de sistemas concurrentes. En concreto, el patrón Producer-Consumer, además de ser extremadamente sencillo, permite optimizar y ajustar el rendimiento de nuestros sistemas dinámicamente jugando con el número de threads afectados. Veamos en qué consiste.
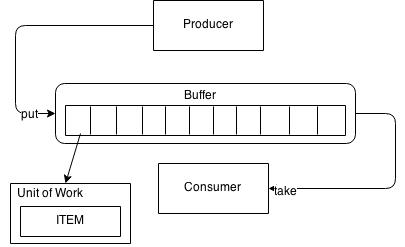
Producer consumer
Los cuatro conceptos a tener en cuenta para implementar este patrón son:
- Ítems: el objeto que es procesado
- Actores: quienes procesan los ítems. Los procesos a realizar sobre los ítems pueden ser creación, cambio de estado o consumo. Los actores correrán en threads diferentes
- Unidades de trabajo: encapsula los ítems para su transferencia entre los actores
- Buffer: es una estructura de datos compartida por los diferentes actores, y que se utiliza para transferir las unidades de trabajo entre ellos utilizando acceso FIFO (First in First out). Podemos verlo también como una “bandeja de transferencia”
Consideraciones a tener en cuenta:
- La idea de utilizar una unidad de trabajo en lugar del ítem para depositar en el buffer es que de esta forma podemos asociar metadatos e información adicional al proceso. Lo veremos mejor en el ejemplo.
- Un actor es considerado productor cuando deposita una unidad de trabajo en el buffer, independientemente de la acción que realice. Es decir, no solo el actor responsable de crear los ítems es considerado productor
- Consumidor es el actor que extrae una unidad de trabajo del buffer para hacer algo con ella. Una vez consumida esta unidad de trabajo por el actor deja de estar disponible para otros consumidores (desaparece del buffer por tanto)
- Un actor puede ser a la vez productor y consumidor, pero en tal caso debe consumir de un buffer y producir en otro
- El buffer ha de estar diseñado para soportar su uso concurrente de forma óptima
Implementación del buffer
Es el factor más importante para que este patrón funcione como es debido. Al ejecutarse los actores en diferentes threads, dependiendo de la acción que realicen sobre el ítem los ritmos de trabajo pueden ser bastante diferentes. De cara a la configuración del buffer esto implica que:
- Si el buffer es de capacidad limitada puede llenarse demasiado rápido, condicionando a los productores
- Si el buffer es de capacidad ilimitada y los productores trabajan mucho más rápido que los consumidores podemos sobrepasar nuestro límite de memoria de la aplicación
Dejando de lado estas consideraciones, lo que en ningún momento queremos es un actor en espera activa y consumiendo recursos intentando depositar una unidad de trabajo en el buffer o tratando de leerla.
La API concurrency de Java contiene varias implementaciones de Queue que solventan la mayoría de estos problemas mencionados. La ventaja más importante es que un thread queda suspendido a la espera de que el buffer esté en el estado deseado para ejecutar la acción requerida, es decir:
- Si intentamos leer un ítem y el buffer está vacío, el thread queda suspendido
- Si intentamos depositar un ítem y el buffer está lleno, el thread queda suspendido
Una vez asimilados todos los precedentes, pasemos a ver las diferentes posibilidades de implementación que tenemos a nuestra disposición en Java.
BlockingQueue
Esta API es una interfaz que extiende a Queue añadiendo operaciones bloqueantes. Es decir, implementa las características que acabamos de comentar. Sin ánimo de profundizar en todas sus operaciones, las que realmente importan son:
putdeposita un elemento en la cola. Operación bloqueante si la cola está llenataketoma un elemento de la cola. Operación bloqueante si la cola está vacía
Las dos principales implementaciones de BlockingQueue son:
ArrayBlockingQueue: respaldada por un array, ha de ser configurada para almacenar hasta un máximo de elementosLinkedBlockingQueue: respaldada por una lista enlazada, no tiene capacidad máxima
Aunque ya lo hemos mencionado previamente, cualquiera de estas dos alternativas presenta un hándicap importante:
- Si el buffer es ilimitado en espacio, y un productor procesa a mucho mayor ritmo que el posterior consumidor podemos desbordar la memoria
- Si limitamos el espacio del buffer podemos crear un cuello de botella entre los diferentes actores, generando más esperas activas de las deseadas.
Para solventar estos problemas, Java 7 introdujo una nueva modalidad de cola bloqueante, TransferQueue.
TransferQueue
Básicamente, TransferQueue es una BlockingQueue con una operación adicional, transfer. Este operación se utilizaría como alternativa a put, y viene a decir “transfiere este elemento a un consumidor, y bloquéate si no existe ningún consumidor disponible”. La única implementación de TransferQueue es LinkedTransferQueue, y se trata de una cola de capacidad ilimitada, lo cual es perfectamente lógico, ya que un productor no podrá insertar elementos en la cola a discreción si no existe un consumidor en el otro lado.
Ejemplo completo
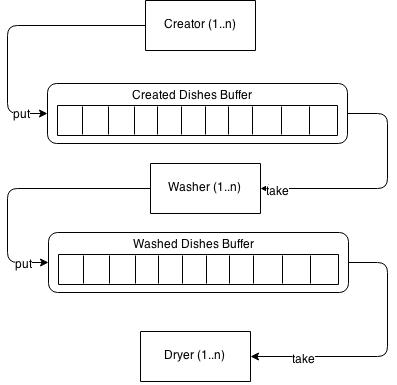
Vamos a crear un ejemplo completo con todos los conceptos que hemos ido revisando. El caso de uso es una “factoría” de platos (Dish), con 3 actores:
Creator: crea las instancia deDishy las deposita en un buffer “createdDishes”. Actúa, por tanto, de productorWasher: lava los platos recién creados y los deposita en el buffer “washedDishes”. Actúa, por tanto, de productor de un buffer y de consumidor de otroDryer: seca los platos lavados, finalizando el proceso. Actúa, por tanto, de consumidor
Pueden existir varias instancias de cada actor, mientras todas ellas compartan el buffer. Además, cada uno de los actores requiere un tiempo determinado para realizar su acción, generando posibles cuellos de botella. En el siguiente diagrama tenemos una vista general del sistema:
Pasemos a ver la implementación. Para poder realizar una comparativa del funcionamiento de las diferentes API’s de Java expuestas más arriba, hemos abstraído el buffer en nuestra propia interfaz:
public interface Buffer<E> {
void put(E element);
E take();
}Con dos implementaciones, la primera respaldada por una BlockingQueue:
public class BlockingQueueBuffer<E> implements Buffer<E> {
private final BlockingQueue<E> queue;
public BlockingQueueBuffer(BlockingQueue<E> queue) {
this.queue = queue;
}
@Override
public void put(E element) {
try {
queue.put(element);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public E take() {
try {
E element = queue.take();
return element;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}Y la segunda respaldada por TransferQueue:
public class TransferQueueBuffer<E> implements Buffer<E> {
private final TransferQueue<E> queue;
public TransferQueueBuffer(TransferQueue<E> queue) {
this.queue = queue;
}
@Override
public void put(E element) {
try {
queue.transfer(element);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@Override
public E take() {
try {
E element = queue.take();
return element;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}Vemos que encapsulamos InterruptedException en una unchecked exception por comodidad en la nueva API. La diferencia entre ambas implementaciones no es muy grande, aparte de la interfaz que las respalda. La única diferencia de hecho es que el método put de TransferQueueBuffer utiliza el método transfer en lugar de put.
El modelo del sistema sería:
public class Dish {
public enum State {CREATED, WET, DRY; }
private final int id;
private State state;
public Dish(int id) {
this.id = id;
state = State.CREATED;
}
public int getId() {
return id;
}
public State getState() {
return state;
}
public void setState(State state) {
this.state = state;
}
}El plato irá cambiando de estado según sea procesado por los diferentes actores.
public class UnitOfWork<T> {
private T item;
private long threadId;
public UnitOfWork(T item) {
this.item = item;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
public long getThreadId() {
return threadId;
}
public void setThreadId(long threadId) {
this.threadId = threadId;
}
}UnitOfWork es una clase genérica, ya que podrá ser utilizada en sistemas similares con otros modelos de datos. Además del ítem, vemos cómo hemos añadido el campo threadId, que indica el identificador del último thread que ha procesado el ítem. Sirva a ejemplo de metadatos asociados a la unidad de trabajo. Gracias a este patrón separamos el objeto a procesar del proceso en sí.
La implementación de los actores sería:
public class Creator implements Runnable {
public static final AtomicInteger sequence = new AtomicInteger(1);
private Buffer<UnitOfWork<Dish>> createdDishesBuffer;
public Creator(Buffer<UnitOfWork<Dish>> createdDishesBuffer) {
this.createdDishesBuffer = createdDishesBuffer;
}
@Override
public void run() {
while(true) {
System.out.println("Creator: creating dish...");
Dish dish = new Dish(sequence.getAndIncrement());
System.out.println("Creator: dish " +
dish.getId() +
" - putting into buffer...");
UnitOfWork<Dish> unitOfWork = new UnitOfWork<Dish>(dish);
unitOfWork.setThreadId(Thread.currentThread().getId());
createdDishesBuffer.put(unitOfWork);
System.out.println("Creator: Dish " +
dish.getId() +
" put into buffer");
}
}
}public class Washer implements Runnable {
private Buffer<UnitOfWork<Dish>> createdDishesBuffer;
private Buffer<UnitOfWork<Dish>> washedDishesBuffer;
public Washer(Buffer<UnitOfWork<Dish>> createdDishesBuffer,
Buffer<UnitOfWork<Dish>> washedDishesBuffer) {
this.createdDishesBuffer = createdDishesBuffer;
this.washedDishesBuffer = washedDishesBuffer;
}
@Override
public void run() {
try {
while(true) {
System.out.println("Washer: waiting to take dish");
UnitOfWork<Dish> unitOfWork = createdDishesBuffer.take();
Dish dish = unitOfWork.getItem();
System.out.println("Washer: took dish " +
dish.getId() +
" - washing...");
Thread.sleep(5000);
dish.setState(Dish.State.WET);
System.out.println("Washer: putting washed dish " +
dish.getId() +
" into buffer");
unitOfWork.setThreadId(Thread.currentThread().getId());
washedDishesBuffer.put(unitOfWork);
System.out.println("Washer: dish " +
dish.getId() +
" put into buffer");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}public class Dryer implements Runnable {
private Buffer<UnitOfWork<Dish>> washedDishesBuffer;
public Dryer(Buffer<UnitOfWork<Dish>> washedDishesBuffer) {
this.washedDishesBuffer = washedDishesBuffer;
}
@Override
public void run() {
try {
while(true) {
System.out.println("Dryer: waiting to take dish");
UnitOfWork<Dish> unitOfWork = washedDishesBuffer.take();
Dish dish = unitOfWork.getItem();
System.out.println("Dryer: took dish " +
dish.getId() +
" - drying...");
Thread.sleep(2000);
dish.setState(Dish.State.DRY);
unitOfWork.setThreadId(Thread.currentThread().getId());
System.out.println("Dryer: dish " +
dish.getId() +
" is dry (done)");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}Todos correrán en un thread de forma indefinida (bucle infinito), y dependiendo de su naturaleza consumirán del buffer, almacenarán en el buffer, o ambas (caso de Washer). Vemos también como los tiempos necesario para cada una de las acciones varían bastante:
Creator: crea instancias sin retardo algunoWasher: añade un retardo de 5 segundos antes de finalizar su acciónDryer: añade un retardo de 2 segundos
Veamos ahora que ocurre cuando utilizamos las diferentes API’s expuestas por Java y levantamos el sistema:
Caso 1: utilizando ArrayBlockingQueue
public static void main(String[] args) {
Buffer<UnitOfWork<Dish>> createdDishesQueue =
new BlockingQueueBuffer<>(
new ArrayBlockingQueue<UnitOfWork<Dish>>(2));
Buffer<UnitOfWork<Dish>> washedDishesQueue =
new BlockingQueueBuffer<>(
new ArrayBlockingQueue<UnitOfWork<Dish>>(2));
Creator creator = new Creator(createdDishesQueue);
Washer washer = new Washer(createdDishesQueue, washedDishesQueue);
Dryer dryer = new Dryer(washedDishesQueue);
new Thread(creator).start();
new Thread(washer).start();
new Thread(dryer).start();
}Hemos limitado el tamaño de los buffer a dos unidades. Cuando ejecutamos esta aplicación el resultado es:
Creator: creating dish...
Washer: waiting to take dish
Dryer: waiting to take dish
Creator: dish 1 - putting into buffer...
Creator: Dish 1 put into buffer
Creator: creating dish...
Creator: dish 2 - putting into buffer...
Creator: Dish 2 put into buffer
Creator: creating dish...
Creator: dish 3 - putting into buffer...
Washer: took dish 1 - washing...
Creator: Dish 3 put into buffer
Creator: creating dish...
Creator: dish 4 - putting into buffer...
(...bottleneck...)
Washer: putting washed dish 1 into buffer
Washer: dish 1 put into buffer
Washer: waiting to take dish
Dryer: took dish 1 - drying...
Creator: Dish 4 put into buffer
Creator: creating dish...
Washer: took dish 2 - washing...
Creator: dish 5 - putting into buffer...
Dryer: dish 0 is dry (done)He añadido artificialmente el lugar donde se crea un cuello de botella. Una vez Washer comienza a procesar su primer ítem, Creator queda bloqueado tras crear el cuarto ítem, ya que son necesarios 5 segundos para lavar el plato, y Dryer siquiera ha entrado en juego. Este cuello de botella existirá en todo momento, y una posible solución podría ser instanciar varios washers:
Creator creator = new Creator(createdDishesQueue);
Washer washer1 = new Washer(createdDishesQueue, washedDishesQueue);
Washer washer2 = new Washer(createdDishesQueue, washedDishesQueue);
Dryer dryer = new Dryer(washedDishesQueue);
new Thread(creator).start();
new Thread(washer1).start();
new Thread(washer2).start();
new Thread(dryer).start();Sin embargo, no parece resultar una solución óptima del todo, de hecho al arrancar el sistema Creator queda bloqueado varios segundos de nuevo tras crear el ítem 5 en esta ocasión (ya que el 1 y 2 son consumidos inmediatamente por los dos threads “washer”). Por supuesto, deberíamos incrementar el tamaño del buffer (2 es una medida escasa, utilizada sólo a modo de ejemplo), pero en tal caso deberemos jugar también con el número de instancias de los actores, y la optimización es compleja.
Caso 2: utilizando LinkedBlockingQueue
Buffer<UnitOfWork<Dish>> createdDishesQueue =
new BlockingQueueBuffer<>(
new LinkedBlockingQueue<UnitOfWork<Dish>>());
Buffer<UnitOfWork<Dish>> washedDishesQueue =
new BlockingQueueBuffer<>(
new LinkedBlockingQueue<UnitOfWork<Dish>>());
Creator creator = new Creator(createdDishesQueue);
Washer washer = new Washer(createdDishesQueue, washedDishesQueue);
Dryer dryer = new Dryer(washedDishesQueue);
new Thread(creator).start();
new Thread(washer).start();
new Thread(dryer).start();En este caso los buffer son de tamaño ilimitado, y ¡las consecuencias son desastrosas! Debido a que la creación de ítems por parte de Creator es casi inmediata, antes de que que se termine de procesar el primer ítem por Washer, ¡se llegan a crear cientos de miles de ítems! De hecho, la salida por consola es irreproducible en este post debido a su magnitud. Mal asunto.
Diría que, en general, el uso de esta implementación de BlockingQueue no es nada recomendable para utilizar el patrón Producer-Consumer, ya que nos obliga a crear otros mecanismos de sincronización si no queremos desbordar la memoria. Y no se trata de eso, ¡sino de delegar la gestión de la concurrencia lo máximo posible!
Caso 3: utilizando LinkedTransferQueue
public static void main(String[] args) {
Buffer<UnitOfWork<Dish>> createdDishesQueue =
new TransferQueueBuffer<>(
new LinkedTransferQueue<UnitOfWork<Dish>>());
Buffer<UnitOfWork<Dish>> washedDishesQueue =
new TransferQueueBuffer<>(
new LinkedTransferQueue<UnitOfWork<Dish>>());
Creator creator = new Creator(createdDishesQueue);
Washer washer = new Washer(createdDishesQueue, washedDishesQueue);
Dryer dryer = new Dryer(washedDishesQueue);
new Thread(creator).start();
new Thread(washer).start();
new Thread(dryer).start();
}Esta es la salida de consola obtenida al ejecutar esta aplicación:
Creator: creating dish...
Creator: dish 1 - putting into buffer...
Washer: waiting to take dish
Dryer: waiting to take dish
Creator: Dish 1 put into buffer
Creator: creating dish...
Creator: dish 2 - putting into buffer...
Washer: took dish 1 - washing...
(bottleneck)
Washer: putting washed dish 1 into buffer
Washer: dish 1 put into buffer
Washer: waiting to take dish
Washer: took dish 2 - washing...
Creator: Dish 2 put into buffer
Creator: creating dish...
Dryer: took dish 1 - drying...
Creator: dish 3 - putting into buffer...
Dryer: dish 1 is dry (done)En este último caso también se crea un cuello de botella, pero hay una diferencia significativa respecto al primer caso. En efecto, Creator queda bloqueado para depositar en la cola la segunda instancia creada, y no la cuarta. Esto es porque la ejecución del thread no continúa hasta encontrar un consumidor disponible para la unidad de trabajo. Hay que tener en cuenta que si el buffer del caso 1 hubiera tenido un tamaño de 1.000 unidades, se habría creado todo ese número de ítems antes incluso de que el primero de ellos fuera procesado por Washer.
Hemos conseguido, por tanto, balancear la carga de trabajo de forma significativa entre los diferentes actores, para no hacerlos procesar “en balde”. A la hora de optimizar este sistema, debemos preocuparnos tan solo del número de instancias de cada actor a crear, y no del tamaño del buffer, lo cual resta bastante complejidad al proceso.
Podríamos crear, por ejemplo, cuatro instancias de Washer, cosa que habría sido algo inútil en el primer caso sin ampliar el buffer:
Creator creator = new Creator(createdDishesQueue);
Washer washer1 = new Washer(createdDishesQueue, washedDishesQueue);
Washer washer2 = new Washer(createdDishesQueue, washedDishesQueue);
Washer washer3 = new Washer(createdDishesQueue, washedDishesQueue);
Washer washer4 = new Washer(createdDishesQueue, washedDishesQueue);
Dryer dryer = new Dryer(washedDishesQueue);
new Thread(creator).start();
new Thread(washer1).start();
new Thread(washer2).start();
new Thread(washer3).start();
new Thread(washer4).start();
new Thread(dryer).start();Conclusión
La API concurrency de Java ofrece diversas alternativas para resolver los problemas tradicionales de multithreading, lo cual no quita que sigan siendo extraordinariamente complejos en ocasiones. Nunca es tarea fácil analizar y mejorar el rendimiento de este tipo de aplicaciones, pero cuanto menor sea el número de puntos a los que hay que prestar atención más sencilla será esta optimización.
Dentro del patrón “Producer-Consumer”, TransferQueue nos permite centrarnos en la configuración de los actores y no en la del buffer, por lo que es una muy buena opción a tener en cuenta.