La revolución Docker
En los últimos doce meses no se habla de otra cosa. Una herramienta cuya primera release fue hace menos de tres años, si las cuentas no me fallan (compañía fundada en 2010), está copando todo tipo de conversaciones, charlas, artículos, blogs…ha sido adoptada por Amazon WS, y casi todas las plataformas Cloud, y su ascensión continúa de modo vertiginoso.
Pero, ¿qué demonios es Docker? Hasta hace relativamente poco yo no lo sabía con toda certeza, pero sí parecía que todo el mundo alucinaba con el tema. Así que al fin me puse manos a la obra, para comprender de forma general en qué consistía, cómo utilizarlo, y qué ventajas ofrece. En este post compartiré con vosotros todo (o casi todo) lo que he aprendido, por si puede servir de referencia.
Precedentes
En la última década se ha incrementando la tendencia a utilizar máquinas virtuales para desplegar aplicaciones. Antes de la implantación de máquinas virtuales el despliegue de una aplicación cualquiera tenía, en general, la siguiente estructura en capas:
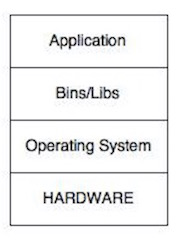
Se trata de un esquema bastante simplificado, y no creo que haya demasiado que explicar aquí. La introducción de máquinas virtuales (sobre todo en entornos de producción) cambió este esquema (a los que las utilicen, claro):
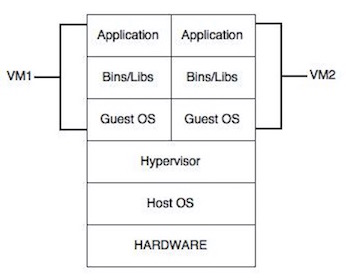
Como vemos, se ha complicado bastante la estrutura de capas de nuestros sistemas. La principal sobrecarga reside en que cada máquina virtual arranca y ejecuta su propia instancia completa del sistema operativo que utilice (Windows, Ubuntu, etc), labor supervisada por la capa Hypervisor (que no es más que la herramienta que gestiona las máquinas virtuales, Virtual Box por ejemplo). De forma que en una máquina en concreto tendremos corriendo al menos dos sistemas operativos diferentes (denominados Host OS y Guest OS, huésped e invitado).
Los inconvenientes de esta arquitectura es que se aumentan considerablemente los requisitos de Hardware de nuestros servidores, pero también lo hace enormemente la estandarización del entorno donde funcionará nuestra aplicación. Al poder crear imágenes base de las máquinas virtuales, ante cualquier problema es fácil reiniciar dicha máquina virtual a una versión limpia en caso de errores, corrupción de archivos, etc. También es muy sencillo escalar horizontalmente, añadiendo instancias de una máquina virtual con un Load Balancer o Balanceador de Carga, para repartir la carga de trabajo. Dado el coste del Hardware hoy día, no es difícil llegar a la conclusión de que los beneficios compensan los inconvenientes.
No es el objeto de este post profundizar demasiado en el uso y beneficios de las máquinas virtuales, así que lo dejaré aquí.
Qué es Docker
Esta es la definición oficial, que aparece en la página de Docker:
Docker is an open platform for building, shipping and running distributed applications. It gives programmers, development teams and operations engineers the common toolbox they need to take advantage of the distributed and networked nature of modern applications.
A mi parecer, esta definición es algo confusa, y no deja demasiado claro qué es Docker. A mi modo de ver, una definición más acertada sería: “Docker es una plataforma que permite la creación de máquinas virtuales Linux muy ligeras a partir de imágenes base. Dichas imágenes son fácilmente distribuibles y configurables, y al ser ejecutadas adoptan el nombre de contenedores (containers)”.
Veamos cómo sería la arquitectura en capas de un servidor utilizando Docker:
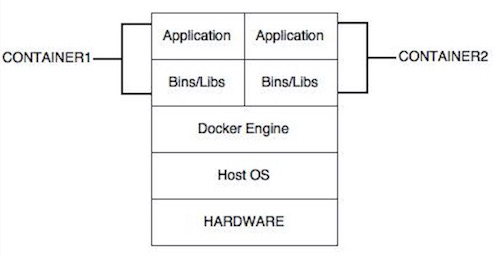
Hemos eliminado la capa “Guest OS” de la ecuación, lo que significa que no es necesario arrancar ningún OS adicional, eliminando una sobrecarga considerable en el proceso de virtualización.
Conceptos principales
Repasemos cuáles son los elementos principales de la plataforma Docker:
- Docker Engine: se trata de la capa encargada de arrancar los contenedores Docker y ejecutar sus aplicaciones
- Imagen: es una máquina virtual Linux ligera (muy ligera), configurada convenientemente para ejecutar determinados comandos o aplicaciones. Una imagen no es un sistema operativo completo, aunque pueda parecerlo (una vez arrancada, podemos abrir una ventana de terminal y navegar en su árbol de directorios, por ejemplo)
- Contenedor: no es más que el nombre que recibe la imagen cuando está en ejecución. Es decir, es una instancia activa de una imagen Docker, con procesos en funcionamiento
- Registro: es un directorio que contiene imágenes Docker listas para usar. Existe uno público ofical, con miles de imágenes. Es posible crear repositorios privados, y cada máquina que use Docker tendrá también disponible un registro local privado. Docker buscará las imágenes en todos ellos
- Dockerfiles: son archivos de texto que permiten crear imágenes a partir de otras, añadiendo ficheros, ejecutando comandos Linux, etc
- Comando docker: a través de este comando y sus opciones explotaremos toda la plataforma
La gran ventaja de Docker es su ligereza. Los contenedores sólo necesitan tener instalados los procesos básicos de cara a desempeñar la tarea para la que han sido creados. Se da el caso de que, en ocasiones, estos contenedores son utilizados para una tarea muy específica, de manera que son arrancados, ejecutados y destruidos de una vez, tarea que además se realiza de forma increíblemente rápida. Lo veremos en el ejemplo. Por supuesto, en otros casos permanecen activos ejecutando un proceso determinado (por ejemplo, sirviendo una base de datos).
Docker está diseñado para funcionar en máquinas Linux (distribuciones Ubuntu, Red Hat, etc), no obstante es posible utlilizarlo también en sistemas OS X o Windows mediante la herramienta Boot2Docker.
“Pues aún no entiendo qué demonios es Docker, quierlo verlo funcionando”. OK, vamos allá.
Docker en la práctica
Voy a exponer un caso de uso muy básico, en el que prácticamente repasaremos todos los conceptos explicados hasta ahora, y veremos la potencia real que tiene esta plataforma.
El objetivo de este ejemplo es compilar, empaquetar y desplegar una aplicación web en un servidor Tomcat. Utilizaremos Maven para la compilación y empaquetado de los fuentes, que descargaremos utilizando Git. Los fuentes están en este repositorio GitHub, acompañados de varios shell scripts y un Dockerfile.
Lo realmente sorprendente de todo esto, es que la única herramienta que necesitamos tener instalada en nuestra máquina para hacer todo, aparte de Git es, ¡Docker! No tenemos que instalar ni Java, ni Maven, ni Tomcat, etc…todas estas herramientas serán utilizadas a través de contenedores Docker. Incluso Git podríamos utilizarlo a través de un contenedor, pero para hacer el ejemplo más directo y replicable vamos a saltarnos esa vuelta de tuerca extra.
Pensad bien en las repercusiones de lo que acabo de decir :), y la potencia que esto tiene en el mundo DevOps, y de desarrollo SW en general.
Manos a la obra, los pasos que vamos a seguir son:
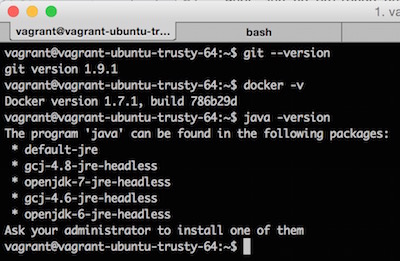
1) Arrancar máquina virtual Vagrant: para que veáis la potencia real de todo esto, he preparado una máquina virtual Ubuntu utilizando Vagrant (del que hablamos con detenimiento aquí). Esta máquina virtual tan solo tiene instalados Git y Docker, y podéis descargar la configuración de mi repositorio GitHub. Para arrancarla, tras instalar Vagrant según cuento en el otro post, vagrant up, y abrid una sesión de terminal con vagrant ssh.
Como podemos ver en la captura, la máquina no tiene instalado Java (ni por extensión, Maven), pero sí tenemos Git y Docker:
2) Descargar los fuentes del repositorio de GitHub:
$ git clone https://github.com/raulavila/spring-mvc-hw.gitSi vamos a la carpeta del proyecto descargado veremos que, aparte del proyecto Maven, hay varios shell scripts y un Dockerfile. Lo primero de todo es dar permisos de ejecución a los ficheros sh:
$ chmod +7 *.sh3) Construir el proyecto: la aplicación no es más que un Hello World utilizando Spring MVC. Recordemos que no tenemos Maven instalado en la máquina, pero sí Docker, así que, utilizando una de las imágenes con Maven instalado (que además contendrán una instalación de Java, por supuesto), vamos a lanzar el proceso de build. El comando completo está en el script build_image.sh con los fuentes, pero reproduciremos aquí el comando Docker completo:
$ docker run -it \
--rm \
--name maven-container \
-v "$PWD":/usr/src/maven-project \
-w /usr/src/maven-project \
maven:3.2-jdk-7
mvn clean packagedocker run ejecuta un comando en el contenedor creado a partir de la imagen especificada. Dicho comando puede ser un servicio que se queda arrancado, y por ende el contenedor, o un proceso que finaliza y al hacerlo para el contenedor (como es este caso). Las imágenes deben existir en algunos de los registros (el oficial público de Docker, uno privado, o el local), y la primera vez que se utilizan, si son externas, son descargadas por Docker, lo que ralentiza esta primera ejecución. Veamos cada una de las opciones utilizadas:
- -it: modo interactivo. Si el comando ejecutado interacciona con el usuario, sus preguntas son redirigidas a la consola de la máquina que está corriendo Docker
- –rm: eliminar al terminar. Al finalizar el proceso el contenedor se para, pero permanecerá disponible para el Docker Engine (aunque parado, “Exited”). El comando –rm elimina esta instancia “latente” del contenedor, dejando disponible tan solo la imagen en el registro local
- –name maven-container: da un nombre al contenedor, si no se utiliza esta opción se le asigna uno por defecto. Para ver los contenedores (en ejecución o latentes) podemos utilizar el comando
docker ps --all:

- -v “$PWD”:/usr/src/maven-project: monta (o mapea) una unidad local en el contenedor que va a ser arrancado. En este caso lo hacemos para que Maven pueda ver los fuentes a compilar y empaquetar, por lo que montamos la ruta actual (
pwd) en el directorio del contenedor/usr/src/maven-project - -w /usr/src/maven-project: directorio de trabajo, donde se ejecutarán por defectos los comandos proporcionados al contenedor
- mvn clean package: comando a ejecutar en el contenedor. En ocasiones las imágenes tienen configurado ya un comando por defecto, por lo que puede omitirse en la llamada
Al finalizar la ejecución de nuestra llamada a docker run tendremos en la carpeta target del proyecto nuestra web empaquetada, bajo el nombre spring-mvc-hw.war. Si volvemos a compilar el proyecto, al estar la imagen Docker en el registro local, podremos comprobar la rapidez con la que todo ocurre, de hecho diría que no existe la percepción de que Maven esté funcionando fuera de la máquina local. A mí esto me resulta bastante increíble. Lo que también veréis es que cada ejecución se descarga todas las dependencias de nuevo, esto es porque cada instancia del contenedor es totalmente nueva, y no tiene cacheadas las dependencias en el repositorio local de Maven. Existen varias formas de resolver esto, montando el repositorio desde una unidad local, por ejemplo. No obstante, el objetivo de este artículo no es optimizar el proceso al 100%, tan sólo mostrar lo que nos ofrece Docker. Sigamos.
4) Construir una imagen Tomcat con la aplicación web empaquetada: aunque podemos arrancar un contenedor Tomcat y desplegar la aplicación web en caliente, nosotros vamos a crear una nueva imagen basándonos en las imágenes Tomcat base del Docker Hub Registry. Esta nueva imagen podría ser distribuida donde quisiéramos y arrancada sin ningún problema en cualquier máquina que soporte Docker (incluyendo plataformas Cloud), subida a un repositorio de nuestra empresa con un tag de versión, o incluso al Docker Hub Registry.
El script que realiza este proceso está en los fuentes (build_image.sh), y su contenido es:
$ docker build -t raul/tomcat .Lo que estamos indicando a Docker es que cree una nueva imagen llamada raul/tomcat basándose en el fichero Dockerfile ubicado en el directorio actual. Tan sencillo como eso. El contenido del fichero Dockerfile es:
FROM tomcat:7-jre7
MAINTAINER "Raul Avila"
ADD target/spring-mvc-hw.war /usr/local/tomcat/webapps/En este caso contiene solo tres líneas:
- Imagen base a utilizar
- Persona encargada de mantener la imagen (lo habitual es indicar nombre y dirección de email)
- Añadir el fichero spring-mvc-hw.war a la carpeta /usr/local/tomcat/webapps de la imagen base. Normalmente la estructura de directorios viene bien documentada en el Docker Hub Registry, pero en cualquier caso siempre podemos abrir un terminal nosotros mismos (por ejemplo, mediante el comando
docker exec -i -t <containerHash> bashsobre un container en ejecución)
Si la imagen está disponible localmente el proceso de creación de esta nueva imagen suele ser bastante rápido. Para ver una lista de las imágenes disponibles ejecutamos el comando docker images:

5) Arrancar la nueva imagen Tomcat: tenemos por tanto una imagen que contiene un Tomcat con nuestra aplicación web instalada y lista para ser publicada. Hagámoslo mediante el script run_image.sh, cuyo contenido es:
$ docker run -d -p 8080:8080 raul/tomcatEn este caso ocurre lo que comenté en el punto 3, la imagen ejecuta un comando por defecto, que no es otro que el que arranca Tomcat, como se puede ver en el fichero Dockerfile de la imagen base. Por tanto no se pasa ningún comando adicional a run. Las opciones son:
- -d: ejecuta el contenedor en modo background. Sin esta opción la salida del contenedor aparecerá en la ventana de terminal y deberemos dejarla abierta si no queremos matarlo
- -p 8080:8080: Tomcat es publicado en el contendor en el puerto 8080, y nosotros queremos que este puerto sea publicado en la máquina local también, esta opción configura este mapeo
6) Abrir la aplicación en nuestro navegador: si vamos a http://localhost:8080/spring-mvc-hw/, ¡podremos ver que la aplicación está funcionando según lo esperado! En cuatro sencillos pasos, y con una máquina totalmente limpia (repito, sólo contiene Git y Docker) hemos conseguido nuestro objetivo.
Conclusión
Aunque este post sea únicamente una introducción, espero que haya servido para hacerse una idea general de la potencia que ofrece esta nueva plataforma. Considero que toda la atención que viene recibiendo últimamente está más que justificada, y realmente puede llegar a cambiar las cosas significativamente en los próximos años.