Integración continua con Concourse CI: conceptos básicos
Concourse CI es una herramienta Open Source de integración continua (aunque realmente es mucho más) que lleva en desarrollo unos dos años. Hace poco se liberó la versión 1.0, y personalmente creo que irá pisando cada vez más fuerte. En esta serie de posts trataré de condensar los principales conceptos que es necesario conocer para ponerse manos a la obra en el menor tiempo posible, y desarrollaré un caso más práctico.
Qué es Concourse
Creo que la mejor forma de definir Concourse sería algo así como “motor de integración continua sobre Docker, cuya configuración solo es posible mediante código y donde los pipelines son ciudadados de primera clase”. Ya hemos hablado de Docker anteriormente en este blog, así que si no lo conocéis os remito a mi post sobre el tema. La mayor ventaja de utilizar Docker es que siempre tendremos un contexto limpio en el que ejecutar las acciones que llevemos a cabo en nuestro entorno de integración continua, por lo que nunca quedan residuos que entorpezcan futuras acciones.
La configuración en código se lleva a cabo mediante ficheros YAML y shell scripts, lo cual ofrece varias ventajas:
- Se puede almancenar la historia de nuestra configuración en un sistema de control de versiones
- Lo más normal es que esta configuración se almacene en una carpeta junto al código fuente de nuestro proyecto, lo cual hace que nuestro pipeline de integración continua y el código de dicho proyecto evolucionen conjuntamente
- Es extremadamente sencillo recrear un pipeline desde cero
- La configuración de Concourse se asemeja mucho más a nuestras tareas de programación diarias, en lugar de tener que utilizar una interfaz web más o menos clara, ¡cosa que es mucho más divertida!
Que los pipelines sean ciudadanos de primera clase significa que el punto de entrada de todos nuestros proyectos de integración continua escritos para Concourse será un fichero que configura un pipeline, ni más ni menos. Nada de build plans, etc. Lo veremos con claridad más adelante.
Instalando Concourse
Aunque existe una versión binaria, la forma más rápida de ponerse manos a la obra con Concourse es mediante una máquina virtual Vagrant. Si no conocéis Vagrant echad un vistazo aquí.
Tras instalar Vagrant en nuestra máquina, solo tenemos que invocar los siguientes comandos:
vagrant init councourse/lite
vagrant upEsto arrancará un servidor Concourse, que escuchará en la dirección http://192.168.100.4:8080/. De hecho si abrimos una ventana en nuestro navegador ya veremos algo:

Este mensaje nos indica que debemos descargar la herramienta CLI fly, ya que es la única forma de configurar nuestro flamante servidor Concourse. Es un binario que deberemos copiar en el PATH de nuestro sistema.
Tras descargar fly, y dado que cada acción requiere indicar de forma explícita la localización de la API Concourse con la que interactuar, conviene crear un alias, de la siguiente forma:
fly --target localconcourse login --concourse-url http://192.168.100.4:8080
fly -t localconcourse syncLo que hemos hecho ha sido crear un alias localconcourse para el servidor que acabamos de arrancar, alias que deberemos utilizar cada vez que hagamos algo en fly, según veremos.
Conceptos básicos
El número de conceptos que debemos conocer para utilizar Concourse es bastante reducido, y en este primer post pasaremos revista a los más básicos:
- Tasks
- Task inputs
- Task ouptuts
- Pipelines (y jobs)
(Mezclaré los términos en inglés y su traducción al castellano durante la explicación de cada uno, espero que no sea confuso)
Task
Una tarea (task) es la unidad básica de trabajo en Concourse. Se trata de una acción determinada a ejecutar en un contenedor Docker, y que debemos configurar en un fichero YAML:
---
platform: linux
image: docker:///debian
run:
path: echo
args: [hello world]En el ejemplo hemos configurado una tarea que correrá sobre el contenedor Docker debian, y ejecutará el comando echo hello world. Simple. Para ejecutar la tarea de forma individual en Concourse deberemos invocar el siguiente comando:
tasks $ fly -t localconcourse execute -c task_hello_world.yml
targeting http://192.168.100.4:8080
executing build 1
initializing with docker:///debian
running echo hello world
hello world
succeededEsto no es muy espectacular, y de hecho será algo que nunca haremos en el mundo real, ya que las tareas formarán siempre parte de pipelines.
Task input
Una tarea puede tener un input, que no es más que una carpeta creada dentro del contenedor Docker por Concourse, que almacenará recursos interesantes para la tarea:
---
platform: linux
image: docker:///debian
inputs:
- name: task_input
run:
path: ls
args: ['-alR']Los inputs se entienden mucho mejor en el contexto de un pipeline. En cualquier caso, si queremos configurar el input de una tarea que estamos ejecutando de manera individual deberíamos hacer:
tasks $ fly -t localconcourse execute -c task_with_input.yml -i task_input=.
targeting http://192.168.100.4:8080
executing build 3
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 10240 0 10240 0 0 4145k 0 --:--:-- --:--:-- --:--:-- 5000k
initializing with docker:///debian
running ls -alR
.:
total 8
drwxr-xr-x 3 root root 4096 May 7 10:22 .
drwxr-xr-x 3 root root 4096 May 7 10:22 ..
drwxr-xr-x 1 501 dialout 78 May 7 10:22 task_input
./task_input:
total 12
drwxr-xr-x 1 501 dialout 78 May 7 10:22 .
drwxr-xr-x 3 root root 4096 May 7 10:22 ..
-rw-r--r-- 1 501 dialout 86 May 7 10:10 task_hello_world.yml
-rw-r--r-- 1 501 dialout 107 May 7 10:20 task_with_input.yml
succeededMediante la opción -i task_input=. indicamos a Concourse que mapee el directorio donde estamos ejecutando el comando fly con el input task_input. Podría ser cualquier otro directorio, por supuesto, y si el directorio que contiene la tarea se llama igual que el input no es necesaria esta opción, realizándose el mapeo automático.
La verdad es que no es muy importante que recordéis como configurar inputs en una tarea individual.
Scripts
Será muy habitual que nuestros inputs contengan scripts a ejecutar dentro del contenedor Docker asociado a la tarea. Creemos por tanto una nueva tarea, task_running_script:
---
platform: linux
image: docker:///debian
inputs:
- name: task_input
run:
path: ./task_input/script.shEl contenido de script.sh es:
#!/bin/bash
echo "I'm a script!"Si ejecutamos un comando similar al de la sección anterior veremos por pantalla el mensaje “I’m a script!” (no reproduczco la salida completa por brevedad). Es importante que el script sea mapeado convenientemente en el input de la tarea, para que esté disponible (¡y no olvidéis dar permisos de ejecución al archivo!).
Output
Un output de una tarea es un directorio que Concourse creará en el contenedor Docker y que nosotros deberemos utilizar para copiar contenidos interesantes durante la ejecución de dicha tarea.
---
platform: linux
image: docker:///debian
outputs:
- name: task_output
run:
path: ls
args: ['-altr']Si ejecutamos esta tarea veremos esto:
tasks $ fly -t localconcourse execute -c task_with_output.yml
targeting http://192.168.100.4:8080
executing build 7
initializing with docker:///debian
running ls -altr
total 8
drwxr-xr-x 1 root root 0 May 7 10:37 task_output
drwxr-xr-x 3 root root 4096 May 7 10:37 ..
drwxr-xr-x 3 root root 4096 May 7 10:37 .
succeededLo cual, de nuevo, tampoco es muy espectacular, pero deja claro que tenemos una carpeta donde copiar lo que queramos (fichero war a desplegar, por ejemplo). Quizás estéis pensando que, ejem, aquí hay un problema, y es que ejecutando una tarea individualmente, cuando esta termina, el contenedor Docker se destruye y el output se pierde. Será dentro de un pipeline donde este concepto cobrará todo su sentido (que supongo que ya intuís).
Pipeline
Llegamos por fin a los pipelines. Un pipeline no es más que un conjunto de jobs (que pueden estar o no conectados entre ellos), siendo un job un conjunto de tasks (que, de nuevo, pueden depender unas de otras, o no). Veamos un ejemplo:
jobs:
- name: job-hello-and-goodbye
public: true
plan:
- task: hello-world
config:
platform: linux
image: docker:///debian
run:
path: echo
args: [hello world]
- task: goodbye
config:
platform: linux
image: docker:///debian
run:
path: echo
args: [goodbye]Este pipeline contiene un job, cuyo plan es un conjunto de dos tareas (sin ninguna relación entre ellas), tareas que se ejecutarán una a continuación de la otra. La diferencia entre la ejecución de un pipeline y de una tarea es que un pipeline no puede ser ejecutado directamente, sino que deberá ser importado en Concourse, de la siguiente forma:
fly -t localconcourse set-pipeline -c pipeline_1.yml -p first_pipeline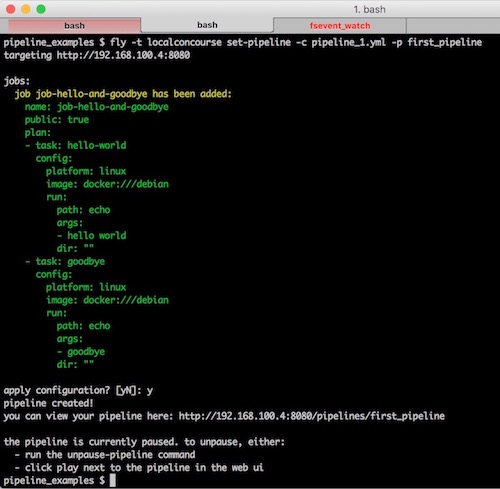
Aquí vemos varias cosas:
- El nombre del pipeline se configura mediante el comando
fly(opción-p), por lo que podemos crear diferentes instancias del mismo pipeline a partir de un mismo fichero YAML de configuración - Concourse nos indica que el pipeline está en modo pausa, esto significa que aunque lo hemos importado no estará activo hasta que lo indiquemos de forma explícita.
Para activar un pipeline podemos utilizar el siguiente comando:
fly -t localconcourse unpause-pipeline -p first_pipelineO bien ir a la UI:
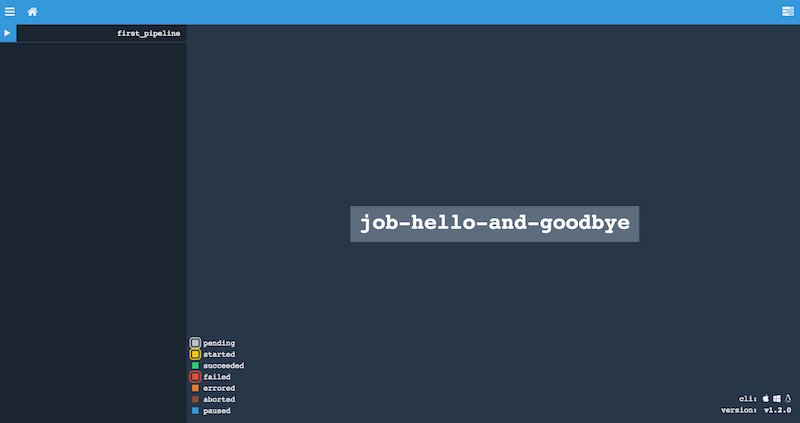
En la esquina superior izquierda vemos un símbolo “Play”, pulsándolo arrancará nuestro pipeline. En este primer ejemplo que hemos creado tenemos un problema, y es que no hemos asociado ningún evento que inicie la ejecución del pipeline, por lo que deberemos hacerlo de forma manual. Para ello haced click sobre la caja del job que aparece en el centro de la pantalla, lo que nos llevará aquí:
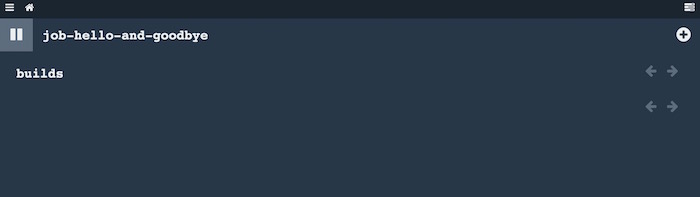
Si pulsamos sobre el símbolo “+” de la esquina superior derecha, nuestro job arrancará:
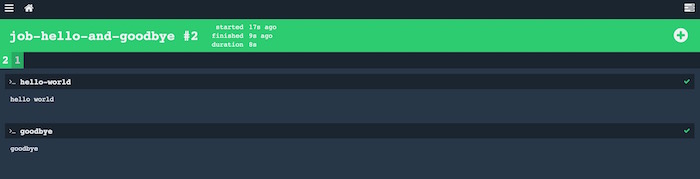
En la pantalla he ejecutado el job dos veces para que veáis el aspecto de la pantalla. Por cada ejecución del job aparece una pestaña con un número que nos permite navegar en la historia, y cada pestaña lista las tareas que componen cada trabajo, y la salida que se ha generado. Por último, aunque en este caso vemos todo verde, si un job fracasa el color sería rojo (claro), mientras se está ejecutando es amarillo, si lo cancelamos es marrón…el código de colores en general es bastante intuitivo.
Para destruir un pipeline deberemos invocar:
fly -t localconcourse destroy-pipeline -p first_pipelineConectando tareas
Para terminar con este primer post, vamos a crear un pipeline donde la primera tarea crea un fichero que será exportado como output para hacerlo disponible en la segunda tarea.
jobs:
- name: job-generate-and-pass-file
public: true
plan:
- task: generate-file
config:
platform: linux
image: docker:///debian
outputs:
- name: generate_file_output
run:
path: touch
args: [generate_file_output/file.txt]
- task: show-file
config:
platform: linux
image: docker:///debian
inputs:
- name: generate_file_output
run:
path: ls
args: ["-altr", "generate_file_output"]Vemos que generate-file crea un fichero file.txt vacío en la carpeta configurada como output. Esta carpeta estará disponible en la siguiente tarea del job, siempre y cuando la configuremos en los inputs (como así hacemos). Por tanto, si listamos los contenidos de esta carpeta input, veremos nuestro fichero:
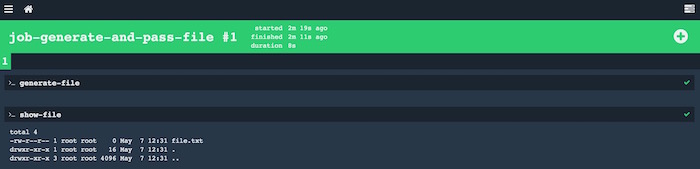
Lo dejamos por hoy. Queda mucho por cubrir, aún estamos lejos de crear un pipeline en condiciones, y nuestros primeros ejemplos, además de tener que lanzarlos de forma manual, solo contienen un job que no interactúa con el mundo exterior. Para hacer algo así, deberemos introducir nuevos conceptos como triggers, resources…pero eso será en el siguiente post.
(Como siempre, los ejemplos utilizados están subidos a GitHub)