Integración continua con Concourse CI: un pipeline real
Finalizaremos con este artículo la serie en torno a Concourse. En posts anteriores nos centramos en crear pipelines sencillos para introducir los diferentes conceptos que es necesario conocer a la hora de utilizar esta herramienta de integración continua. Sin embargo, ninguno de esos pipelines se asemejaba demasiado a los que utilizaremos en nuestros proyectos del día a día. Ha llegado la hora de presentar un ejemplo más real.
Supongo que a casi todos los que estáis leyendo estas líneas os resultará más o menos familiar tener un servidor de CI que a cada commit en el repositorio de control de versiones y/o de manera periódica (cada hora, cada noche, etc), construye el proyecto, ejecutando todos los tests, de manera que el equipo de desarrollo es informado de manera inmediata sobre el estado del código. De forma adicional, si el build es exitoso, podríamos querer desplegar la nueva versión en algún entorno de pruebas, por ejemplo. Va a ser justamente esto lo que configuraremos a continuación, pero antes vamos a introducir un nuevo elemento que quizás os resulte desconocido…
Cloud Foundry
Cloud Foundry es una plataforma como servicio (PaaS - Platform As A Service) de código abierto que nos ofrece un entorno de ejecución en la nube para nuestras aplicaciones. Estas aplicaciones pueden estar desarrolladas en prácticamente cualquier lenguaje que se os pueda pasar por la cabeza, y Cloud Foundry se encargará de proveer los recursos adecuados para cada tecnología en concreto.
Podemos crearnos nuestra propia instalación en servidores propios, podemos crear una instancia en Amazon Web Services, suscribirnos a la versión comercial ofrecida por Pivotal (Pivotal Web Services), o incluso utilizar una versión empaquetada en una máquina virtual Vagrant (PCF Dev, adecuada únicamente para el desarrollo).
No es el objetivo de este posts profundizar demasiado en la herramienta, Internet está plagado de recursos. A efectos de este post, lo único que necesitamos saber es que, una vez empaquetada nuestra aplicación (en nuestro caso como fichero jar), el despliegue en Cloud Foundry se realiza mediante una API que solo necesita saber el valor de cuatro parámetros:
usernamepasswordorganizationspace
Los dos primeros son obvios, organization viene a ser el equivalente a un proyecto, mientras que space nos ayuda a identificar entre diferentes entornos (desarrollo, test, producción, etc). A continuación veremos de qué forma tan transparente Concourse interactúa con Cloud Foundry, cosa que no debería sorprender una vez sabes que Concourse se creó precisamente para configurar pipelines dentro del propio proyecto Cloud Foundry :)
El pipeline
Vamos a montar un pipeline para construir y desplegar el proyecto ubicado en https://github.com/raulavila/spring-boot-hello-world.git. No es más que una sencilla aplicación web “Hello World”. El pipeline se pondrá en marcha cada vez que alguien suba cambios a Git, o, de manera alternativa, cada 30 minutos. Los jobs que compondrán el pipeline serán:
- Uno que validará nuestro código ejecutando la suite de test completa
- Un segundo que empaquetará el proyecto como fichero
jary lo subirá a Cloud Foundry. Este job sólo se ejecutará si el primero es exitoso (si todos los tests tienen éxito)
Ya tenemos todos los ingredientes necesarios para configurar el pipeline. Si habéis leído los dos posts anteriores no tendréis excesiva dificultad en comprender el siguiente fichero YAML:
---
resources:
- name: pipeline-code
type: git
source:
uri: https://github.com/raulavila/concourse-examples.git
- name: source-code
type: git
source:
uri: https://github.com/raulavila/spring-boot-hello-world.git
- name: cloud-foundry
type: cf
source:
api: https://api.run.pivotal.io
username: {{cf-email}}
password: {{cf-password}}
organization: {{cf-org}}
space: {{cf-space}}
skip_cert_check: false
- name: every-30m
type: time
source:
interval: 30m
jobs:
- name: job-build-and-test
public: true
plan:
- get: pipeline-code
- get: source-code
trigger: true
- get: every-30m
trigger: true
- task: verify
file: pipeline-code/pipeline_real/tasks/task_verify.yml
privileged: true
- name: job-cf-deploy
public: true
plan:
- get: pipeline-code
- get: source-code
trigger: true
passed: [job-build-and-test]
- get: every-30m
trigger: true
- task: package
file: pipeline-code/pipeline_real/tasks/task_package.yml
privileged: true
- put: cloud-foundry
params:
manifest: cf-deploy-files/manifest.ymlVemos que:
- Tenemos cuatro resources: dos de ellos hacen referencia a los repositorios Git que contiene el código fuente y el código del pipeline, respectivamente. El tercero es un resource de tipo time (para establecer ejecuciones periódicas del pipeline), y el último es el resource que representa la instancia de Cloud Foundry que vamos a utilizar
- Vemos que el resource
cloud-foundryse configura mediante los parámetros que mencionamos anteriormente, además de la URL de la API - El primer job se descarga los recursos git, y ejecuta la tarea
verify, cuyo fichero YAML contiene:
---
platform: linux
image: docker:///maven
inputs:
- name: pipeline-code
- name: source-code
run:
path: pipeline-code/pipeline_real/scripts/verify.shVemos que utilizamos el contenedor Docker maven, ya que Maven será la herramienta con la que gestionaremos nuestro proyecto Java. A su vez, el script verify.sh contiene:
#!/bin/bash
cd source-code
mvn clean verify- El segundo job, que está ligado al éxito del primero (mediante el parámetro
passed), construye el fichero desplegable, y lo pone a disposición de la siguiente tarea mediante outputs.
---
platform: linux
image: docker:///maven
inputs:
- name: pipeline-code
- name: source-code
outputs:
- name: cf-deploy-files
run:
path: pipeline-code/pipeline_real/scripts/package.sh#!/bin/bash
cd source-code
mvn clean package -DskipTests
if [ $? -ne 0 ]; then
exit 1
fi
cp manifest.yml ../cf-deploy-files
cp target/hello-world-0.0.1-SNAPSHOT.jar ../cf-deploy-filesVemos que construimos el proyecto sin ejecutar los tests esta vez. No es necesario, puesto que el job anterior ya ha verificado nuestro código desde ese punto de vista
El fichero manifest.yml, que copiamos en la salida de la tarea, es el fichero utilizado por los clientes de Cloud Foundry para configurar parámetros adicionales (como ruta donde vamos a exponer nuestra aplicación, cantidad de memoria a utilizar, etc). No es el cometido de este artículo profundizar demasiado en ello, pero a modo informativo, el contenido del fichero en nuestro ejemplo es:
---
applications:
- name: spring-boot-hello-world
path: hello-world-0.0.1-SNAPSHOT.jarSencillo, se trata del nombre de la aplicación y del fichero que queremos subir a Cloud Foundry.
La última tarea del job job-cf-deploy, put, va asociada al recurso cloud-foundry, y creo que resulta evidente lo que hace. En la jerga CF ejecuta un cf push, es decir, la subida de los contenidos configurados en el fichero manifest.yml que se le pasa como parámetro.
Configuración de variables
No hay prácticamente nada en este pipeline que no haya sido cubierto en las entregas anteriores, excepto una cosa. Os preguntaréis dónde estamos configurando los valores de los parámetros asociados al resource cloud-foundry:
- name: cloud-foundry
type: cf
source:
api: https://api.run.pivotal.io
username: {{cf-email}}
password: {{cf-password}}
organization: {{cf-org}}
space: {{cf-space}}
skip_cert_check: falseLos parámetros configurados mediante el patrón {{variable}}
son, pues eso, parámetros, que, o bien pueden variar entre diferentes instancias del mismo pipeline, o contiene secretos que no queremos hacer públicos (en general se tratará de esto último).
Para configurar el valor de estos parámetros deberemos crear un fichero YAML aparte en la siguiente forma:
cf-email: email@email.com
cf-password: password
cf-org: my-org
cf-space: my-spacePongamos que el nombre de este fichero es secrets.yml (¡no olvidéis añadirlo al fichero .gitignore!). Lo único que deberemos añadir es la opción -l a nuestro comando fly cuando creemos o actualizemos el pipeline, es decir: fly sp -t localconcourse -c pipeline.yml -p build-deploy-cf -n -l secrets.yml.
Veamos el aspecto final de nuestro pipeline:
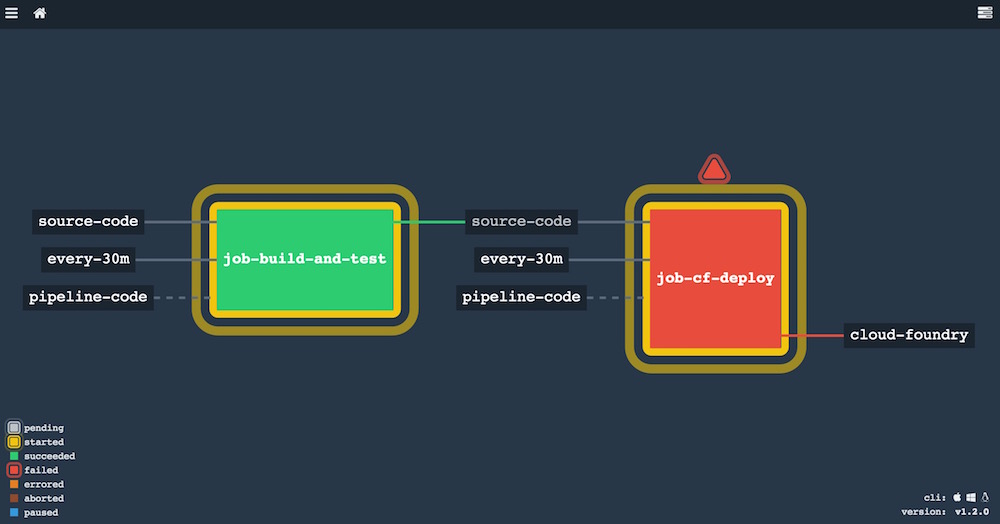
En la captura uno de los jobs ha fracasado, porque no siempre funciona todo en este mundo, ¿verdad? Además, el pipeline está en ejecución ahora mismo, de ahí las auras amarillas en torno a cada job. Si os preguntáis por qué ambos jobs están en ejecución a la vez, se trata de una situación perfectamente posible, ya que puede ocurrir que Concourse ejecute a la vez el final de un pipeline y un nuevo inicio del mismo.
Para consultar los logs generados deberíamos hacer click sobre cada job, tal y como vimos en las primeras entregas.
Otras consideraciones
Si seguís este tutorial detectaréis que, al ejecutarse cada tarea en un contenedor Docker limpio, Maven necesita descargarse todas las dependencias en cada ejecución. Esto penaliza bastante el tiempo medio para ejecutar el pipeline completo, y en la vida real la solución más sencilla sería crear una imagen Docker con todas las dependencias cacheadas, y utilizar dicha imagen en lugar de la oficial de Maven.
El catálogo de resources de Concourse es amplio, y es muy sencillo añadir acciones como enviar emails ante determinados eventos, crear un pull request en Git, ¡o incluso publicar un tweet! Echad un vistazo vosotros mismos. Concourse es una herrramienta muy joven, por lo que previsiblemente este catálogo de recursos no dejará de crecer.
Conclusiones
Concourse es una herramienta muy potente, con la flexibilidad como mayor baza. Aunque aún le quede camino por recorrer, creo que merece la pena echarle un vistazo y evaluar si nos conviene utilizarlo en lugar de otras opciones como Jenkins o Bamboo.
A nivel personal, una de las cosas que más me gusta de Concourse es que configurar pipelines se asemeja mucho al proceso habitual de desarrollo (¡incluyendo refactoring!), lo cual lo hace muy disfrutable. Otra gran baza es su simplicidad visual, que lo hace perfecto para tenerlo siempre visible en un monitor de la oficina y detectar cuanto antes cualquier incidencia, reduciendo los tiempos de feedback.
(El código de este post está disponible aquí)