Integración continua con Concourse CI: conceptos avanzados
Seguimos con Concourse. En el anterior post introdujimos la herramienta y los conceptos básicos que hay que conocer necesariamente para escribir un job sencillo. Sin embargo, quedamos lejos de poder implementar un pipeline real, nuestro primer pipeline solo tenía un job y había que lanzarlo de forma manual. Será en este segundo post de la serie donde nos acercaremos mucho más a un uso práctico de Concourse.
Resources
Para refrescar la memoria, recordemos como dejamos nuestro último pipeline:
jobs:
- name: job-generate-and-pass-file
public: true
plan:
- task: generate-file
config:
platform: linux
image: docker:///debian
outputs:
- name: generate_file_output
run:
path: touch
args: [generate_file_output/file.txt]
- task: show-file
config:
platform: linux
image: docker:///debian
inputs:
- name: generate_file_output
run:
path: ls
args: ["-altr", "generate_file_output"]No profundizaré en lo que pasa aquí, ya hablamos sobradamente de ello. Vemos que toda la configuración de nuestro pipeline (en este caso, se trata básicamente de las tareas) está configurada en un solo fichero, el fichero YAML del pipeline. En la práctica esto no es muy conveniente, ya que las tareas serán de mayor o menor complejidad, y lo suyo es que el pipeline sea una representación a alto nivel de las tareas que contiene, abstrayendo los detalles particulares.
Necesitamos, por tanto, extraer nuestas tareas a ficheros independientes, que serán utilizados en la configuración del pipeline. Para conseguir esto necesitamos introducir un nuevo concepto a nuestra caja de herramientas, los Resources. Un resource de Concourse no es más que una entidad externa que puede servir de entrada o salida en nuestros pipelines. En la documentación oficial podéis profundizar en los diferentes tipos de resources, pero estos pueden ser cosas tan variadas como el tiempo, un repositorio Git, una instancia de Cloud Foundry, un bucket de Amazon S3, etc. Incluso podemos crear nuestros propios resources si no encontramos lo que buscamos en la comunidad.
El resource más común es git. Esto es así porque Concourse no permite almacenar ficheros directamente en el servidor, sino que deben ser provistos desde fuera. La única información que podemos cargar a Concourse sin utilizar resources es la configuración de nuestro pipeline, es decir, todo lo que podamos especificar en un fichero pipeline.yml, pero nada fuera de él.
Pipeline as code
Vamos por tanto a configurar nuestro pipeline en un repositorio Git que será descargado en cada ejecución. Lo primero será extraer las dos tareas del job en ficheros independientes, que quedarán así:
- task_generate_file.yml
---
platform: linux
image: docker:///debian
outputs:
- name: generate_file_output
run:
path: touch
args: [generate_file_output/file.txt]- task_show_file.yml
---
platform: linux
image: docker:///debian
inputs:
- name: generate_file_output
run:
path: ls
args: ["-altr", "generate_file_output"]No hay mucha historia aquí, ya vimos anteriormente como crear ficheros YAML con tareas. El salto importante se produce en el fichero de pipeline:
---
resources:
- name: pipeline-code
type: git
source:
uri: https://github.com/raulavila/concourse-examples.git
jobs:
- name: job-generate-and-pass-file
public: true
plan:
- get: pipeline-code
- task: generate-file
file: pipeline-code/pipeline_tasks/task_generate_file.yml
- task: show-file
file: pipeline-code/pipeline_tasks/task_show_file.ymlVemos que:
- Hemos configurado un nuevo elemento,
resourcesdonde configuramos un repositorio Git. Podemos tener tantos resources como queramos - Nuestro build plan contiene tres tareas: la primera descarga el resource
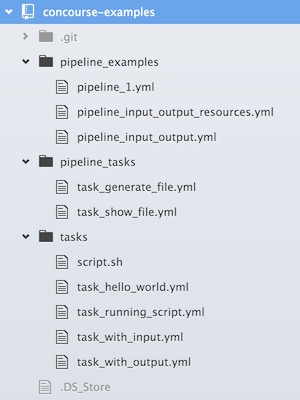
pipeline-codey las otras dos tareas son el equivalente a las que teníamos en la versión anterior del pipeline, solo que esta vez su configuración está en ficheros independientes que viven en el repositorio Git del pipeline. Lo más destacable aquí es que todos los resources Git que descarguemos en nuestro build plan pueden utilizarse en la configuración del pipeline, y podrán ser mapeados como inputs en los contenedores Docker que ejecutan el resto de tareas del plan. El nombre del directorio utilizado como input coincidirá con el nombre del resource, por eso vemos que accedemos a las tareas comopipeline-code/pipeline_tasks/task_generate_file.yml, por ejemplo. Para no dejar lugar a dudas, esta es la estructura de nuestro repositorio Git del pipeline:
Si actualizamos el pipeline (fly -t localconcourse set-pipeline -c pipeline_input_output_resources.yml -p input_output_pipeline), y vamos a la UI (http://192.168.100.4:8080/), tenemos esto:
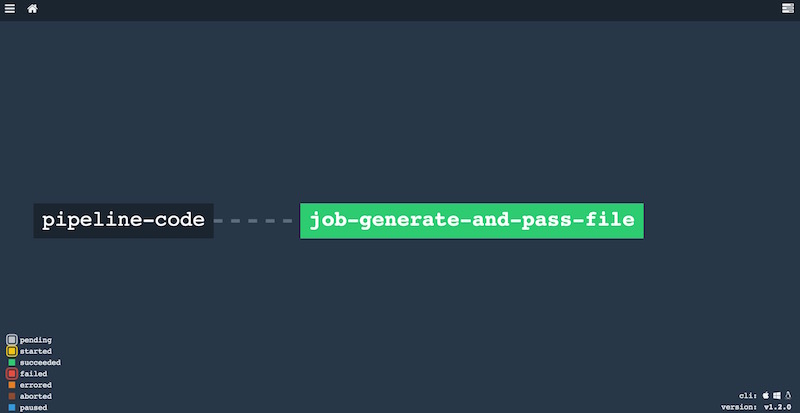
Vemos que el resource y el job están unidos por una linea discontinua, esto significa que están asociados, de forma que las tareas de nuestro job pueden acceder al resource, pero que no hemos configurado ningún evento en el resource que ejecute el job automáticamente. Lo veremos en la siguiente sección.
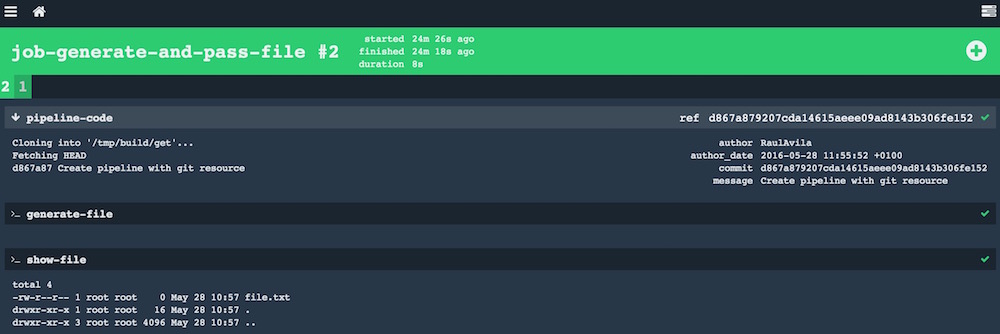
Por último, echemos un vistazo a la salida producida al ejecutar nuestro nuevo build plan, creo que la captura es bastante auto-explicativa:
Tareas en scripts
Vamos a dar una vuelta de tuerca adicional extrayendo las acciones ejecutadas en las tareas de Concourse en shell scripts. Esta viene a ser la fórmula habitual, es decir, tendremos tres niveles, pipeline -> tareas -> sripts. En esta nueva versión del código de nuestro pipeline, el fichero YAML del pipeline permanece igual, pero nuestras tareas quedarán así:
- task_generate_file.yml
---
platform: linux
image: docker:///debian
inputs:
- name: pipeline-code
outputs:
- name: generate_file_output
run:
path: pipeline-code/pipeline_scripts/generate_file.sh- task_show_file.yml
---
platform: linux
image: docker:///debian
inputs:
- name: pipeline-code
- name: generate_file_output
run:
path: pipeline-code/pipeline_scripts/list_files.shVemos que es necesario configurar como input el resource pipeline-code, de otra manera no sería mapeado dentro del contenedor Docker por Concourse. Creo que queda claro que hemos extraído los comandos de nuestras tareas en dos ficheros, generate_file.sh y list_files.sh, ambos ubicados en la carpeta pipeline_scripts del repositorio Git.
Triggers
Comentaba que nuestro repositorio Git está asociado al job, pero aún tenemos que ejecutar nuestro pipeline de forma manual. Para solucionar esto tenemos los triggering resources, que no es más que configurar un resource dentro del build plan para que lance la ejecución de forma automática ante determinados eventos. Si nuestro resource es un repositorio Git, el evento será la subida de una nueva versión, evidentemente. Para configurar un trigger solo tenemos que añadir el atributo trigger a la tarea get asociada al resource:
jobs:
- name: job-generate-and-pass-file
public: true
plan:
- get: pipeline-code
trigger: true
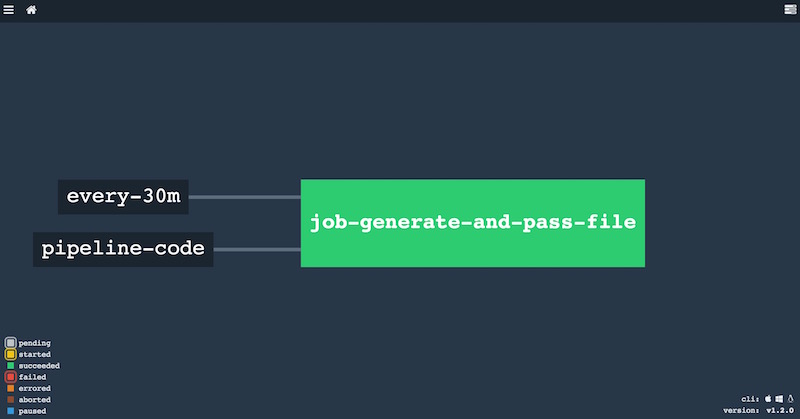
.....Si actualizamos el pipeline, vemos que la UI cambia el formato de la linea que asocia resource y job:
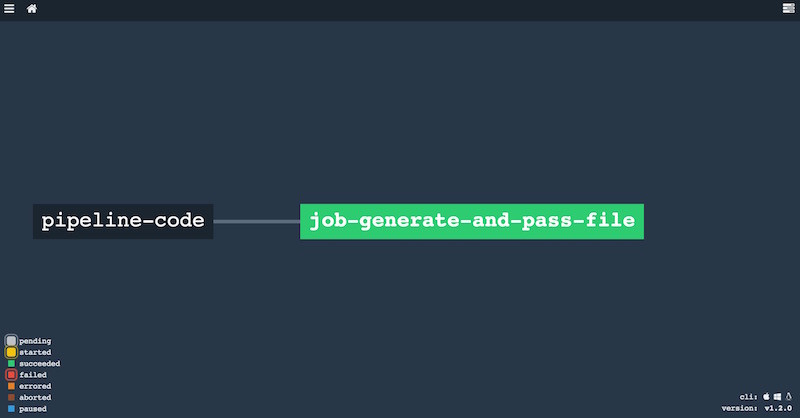
Desde este momento, nuestro pipeline será lanzado si el repositorio Git es actualizado con un nuevo commmit.
Es muy habitual que queramos comprobar el estado de nuestros pipelines cada cierto tiempo, independientemente de que actualicemos el código fuente o no. Para esto existe el resource time, que añadido a nuestro fichero YAML de configuración quedaría tal que así:
---
resources:
- name: pipeline-code
type: git
source:
uri: https://github.com/raulavila/concourse-examples.git
- name: every-30m
type: time
source:
interval: 30m
jobs:
- name: job-generate-and-pass-file
public: true
plan:
- get: pipeline-code
trigger: true
- get: every-30m
trigger: true
- task: generate-file
file: pipeline-code/pipeline_tasks/task_generate_file.yml
- task: show-file
file: pipeline-code/pipeline_tasks/task_show_file.ymlDe esta forma, ahora tenemos dos eventos que pueden lanzar la ejecución del pipeline, la actualización del código fuente, y una ejecución programada cada 30 minutos. Sencillo, ¿verdad?
Conectando jobs
Para terminar esta segunda parte de la serie, veremos cómo conectar dos jobs de un pipeline, cosa que será bastante habitual en la práctica. Aunque un job puede contener un número indeterminado de tareas, y la forma en que se ejecutan dichas tareas hace que el propio job sea una especie de “mini-pipeline” (porque si una tarea falla ahí termina la ejecución del job), a nivel visual es conveniente separar responsabilidades en diferentes jobs. Por ejemplo, puede que queramos tener un job que construya el proyecto y ejecute los tests, y otro que despliegue la aplicación es un entorno concreto. En la última parte de esta serie de posts configuraremos un pipeline de este tipo, hoy solo veremos como conectar dos jobs.
La forma de conectar dos jobs en Concourse puede resultar un poco extraña a priori. La idea es que para que la ejecución exitosa de un job (porque evidentemente si falla el pipeline no debe continuar) lance otro a continuación, debemos conectar ambos jobs mediante un resource:
---
...
jobs:
- name: job-generate-and-pass-file
public: true
plan:
- get: pipeline-code
trigger: true
...
- name: job-confirm-previous-is-done
public: true
plan:
- get: pipeline-code
trigger: true
passed: [job-generate-and-pass-file]
- task: say-done
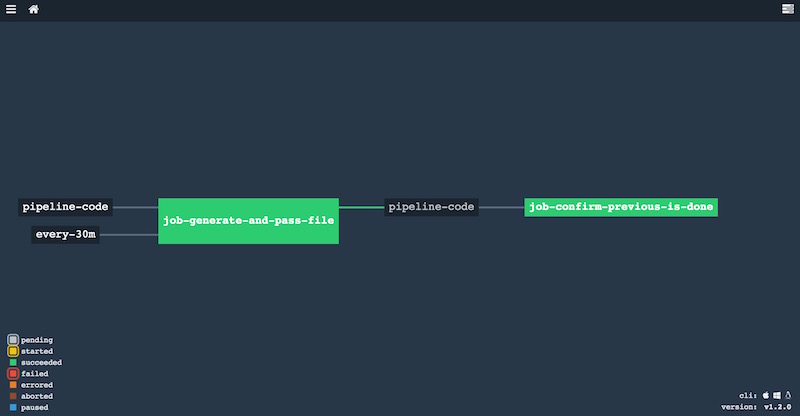
file: pipeline-code/pipeline_tasks/task_say_done.ymlEn esta versión reducida del pipeline (aquí tenéis la versión completa), vemos como existen dos jobs, job-generate-and-pass-file y job-confirm-previous-is-done, y solo queremos ejecutar el segundo si el primero tiene éxito. Un job no puede depender de otro si el primero no le pasa ninguna información, y en Concourse esto se hace mediante un resource. Por tanto, en este pipeline de ejemplo hemos designado al resource pipeline-code como el encargado de conectar ambos jobs, y la forma en que indicamos que solo queremos lanzarlo si el primero termina correctamente es mediante el parámetro passed. Observad que es un array, lo que significa que podemos condicionar la ejecución de un job a la finalización de varios jobs previos.
Este pipeline es un poco artificial, ya que realmente el primer job no está publicando nada en el resource Git. En un pipeline más real haríamos cosas como subir un fichero war a un bucket S3, por ejemplo. No obstante, en ocasiones esta configuración es perfectamente válida, ya que el 99,99% de los jobs deberán obtener un recurso (aunque solo sea el código del pipeline), y este lugar será el candidato perfecto para asociar jobs. Tened en cuenta que una ejecución manual del primer job no lanzará el segundo si el resource que los asocia no es actualizado (acción que es la que realmente dispara la ejecución de ambos).
Para terminar, veamos como queda nuestro pipeline en la UI:
Lo dejamos por hoy, en el siguiente (y seguramente último) post de la serie configuraremos un pipeline más cercano a la realidad cotidiana de nuestros proyectos.