Cómo funciona Git (parte 2)
En el primer post de esta serie comenzamos a destripar el funcionamiento interno de Git, revisando los diferentes tipos de datos que Git soporta internamente. Si no lo habéis leído deberíais empezar por ahí.
Dejamos nuestro repositorio en el siguiente estado:
.
└── hello.txtEs decir, un directorio con un fichero hello.txt, fichero que contiene el texto “Hello World”. Tras hacer nuestro primer commit y añadir un tag, nos quedó la siguiente estructura interna:
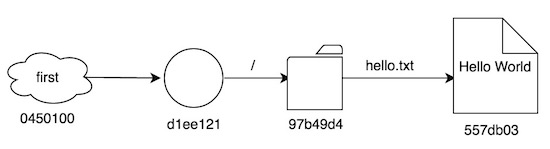
Seguiremos trabajando desde aquí.
Segundo commit
Vamos a añadir una nueva carpeta greetings, que contendrá un fichero, hello2.txt con el mismo texto “Hello World”:
$ mkdir greetings
$ cd greetings
$ cp ../hello.txt .
$ mv hello.txt hello2.txt
$ cd ..
$ tree
.
├── greetings
│ └── hello2.txt
└── hello.txt
1 directory, 2 files
$ git add .
$ git commit -m "Second commit"
[master 284c288] Second commit
1 file changed, 1 insertion(+)
create mode 100644 greetings/hello2.txtTras estas operaciones, nuestra carpeta .git/objects contiene ahora 7 objetos:
├── objects
│ ├── 04
│ │ └── 50100369ff9e0b980dfc6ae42aaeb1de6890f6
│ ├── 28
│ │ └── 4c288acedfc52626386bbf134465f073cf2990
│ ├── 4a
│ │ └── f5100442a48dd4b8a53e4cb05b848d0336d8d7
│ ├── 55
│ │ └── 7db03de997c86a4a028e1ebd3a1ceb225be238
│ ├── 97
│ │ └── b49d4c943e3715fe30f141cc6f27a8548cee0e
│ ├── d1
│ │ └── ee121d5fe96b891ac0cc695498f31c0a4a7664
│ ├── ee
│ │ └── 6b307ad7ed6204ec4331aa38c04ea73b684287
│ ├── info
│ └── packComparando con la versión anterior, tenemos tres nuevos objetos, vamos a revisarlos de forma individual, y comprobar cómo ha quedado la estructura en forma de árbol.
284c28, es el objeto que contiene la información del segundo commit:
$ git cat-file -t 284c28
commit
$ git cat-file -p 284c28
tree ee6b307ad7ed6204ec4331aa38c04ea73b684287
parent d1ee121d5fe96b891ac0cc695498f31c0a4a7664
author RaulAvila <xxxxx@gmail.com> 1486816422 +0000
committer RaulAvila <xxxxx@gmail.com> 1486816422 +0000
Second commitEste commit se diferencia del primero en que tiene un parent, d1ee12, que no es más que el primer commit. Esta es la forma en que Git controla el histórico enlazando commit sucesivos. También vemos que nuestro commit referencia a un nuevo tree, ee6b30, el segundo objeto añadido con este commit:
$ git cat-file -t ee6b30
tree
$ git cat-file -p ee6b30
040000 tree 4af5100442a48dd4b8a53e4cb05b848d0336d8d7 greetings
100644 blob 557db03de997c86a4a028e1ebd3a1ceb225be238 hello.txtEste objeto tree es el nuevo root de nuestro proyecto. Vemos que este root ahora contiene el fichero hello.txt, que no ha cambiado respecto al primer commit, por lo que sigue estando contenido en el objecto 557db0, y la nueva carpeta, que está almacenada en git como un nuevo objeto tree, 4af510:
$ git cat-file -t 4af510
tree
$ git cat-file -p 4af510
100644 blob 557db03de997c86a4a028e1ebd3a1ceb225be238 hello2.txtEl contenido de la carpeta es un puntero al contenido (blob) del nuevo fichero, de nombre hello2.txt. ¿Notáis algo llamativo? En efecto, el hash al que apunta este tree es también 557db0, esto es así porque ambos ficheros contienen la misma información, de forma que el hash calculado es idéntico.
Con todo esto, veamos cómo queda nuestro árbol de objetos:
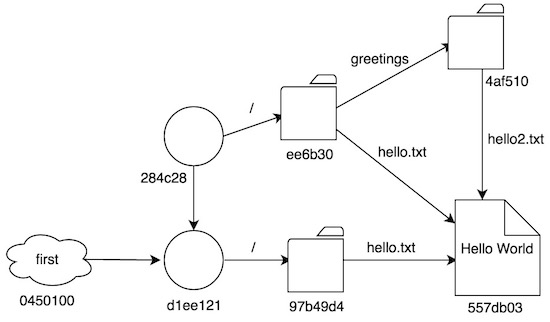
Este va a ser el diagrama más complicado que veremos en la serie, y espero que más o menos haya quedado claro. Git intenta reutilizar toda la información que sea posible al añadir nuevos commits, y así, el blob “Hello World” es apuntado desde tres lugares diferentes (el fichero del primer commit, el mismo fichero del segundo, y el nuevo fichero del segundo). De esta forma se minimiza la cantidad de datos creados por cada cambio. Además, las carpetas info y pack se utilizan en procesos de compresión que no cubriremos aquí (para empezar, porque no los conozco todavía :)).
A continuación veremos una de las funcionalidades más potentes de Git, y os asombraréis de lo sencilla que es su implementación.
Ramas
Para comprender bien el funcionamiento de las ramas (branches) en Git, vamos a simplificar el diagrama de la estructura que hemos ido creando, y nos quedaremos únicamente con los commits:
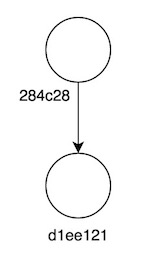
Todos sabemos que cuando iniciamos un proyecto Git, este nos crea con nuestro primer commit una única rama de nombre master. Internamente, una rama es algo tan tonto como un pequeño ficherito que apunta a un commit, ni más ni menos, es decir, un alias:
$ cat .git/refs/heads/master
284c288acedfc52626386bbf134465f073cf2990Como véis, el contenido de este fichero es el hash del último commit que hemos realizado:
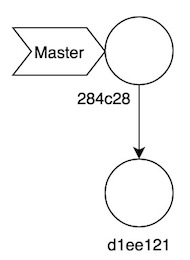
La gran diferencia entre tags y ramas es que los tags son inmutables, mientras que las ramas están “vivas”, avanzando con cada commit añadido a la historia.
Vamos a crear una nueva rama apuntando al mismo commit:
$ git branch develop
$ cat .git/refs/heads/develop
284c288acedfc52626386bbf134465f073cf2990Sin demasiadas sorpresas, la nueva rama apunta al commit en que nos encontramos, coincidendo con master, es decir:
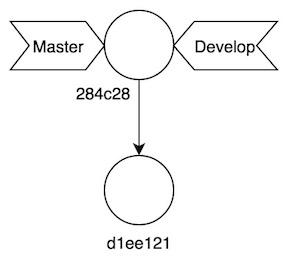
La pregunta aquí es qué rama será la que avanzará si añadimos un nuevo commit, veámoslo en vivo:
$ echo "Goodbye" > goodbye.txt
$ git add .
$ git commit -m "Third commit"
[master aa90e47] Third commit
1 file changed, 1 insertion(+)
create mode 100644 goodbye.txt
$ cat .git/refs/heads/master
aa90e471ababde242281c833fffea255f69dd28a
$ cat .git/refs/heads/develop
284c288acedfc52626386bbf134465f073cf2990
$ git branch
develop
* masterEn efecto, seguimos en master, porque git branch tan solo crea una rama en el actual commit sin ponerla como rama activa. Para conseguir esto deberíamos hacer:
$ git checkout develop
Switched to branch 'develop'
$ git branch
* develop
masterAhora sí, nuestra rama activa es develop, y si añadimos un nuevo commit no será asociado a master hasta que realicemos un merge o un rebase (volveremos sobre esto en el siguiente post). Como alternativa, podríamos crear una nueva rama y movernos a ella en un paso con git checkout -b rama.
¿Cómo almacena Git la información de la rama activa? Pues muy sencillo, en el fichero .git/HEAD, que en realidad no es más que un fichero de texto apuntando al lugar en que nos encontramos dentro del histórico (es decir, un puntero a un puntero). De hecho este fichero no tiene por qué apuntar a una rama, puede hacerlo a un commit determinado si hacemos un git checkout <hash>, lo que se conoce como “detached HEAD”. Veamos varios ejemplos de esto:
$ git branch
* develop
master
$ cat .git/HEAD
ref: refs/heads/develop
$ git checkout master
Switched to branch 'master'
$ cat .git/HEAD
ref: refs/heads/master
$ git checkout aa90e47
Note: checking out 'aa90e47'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at aa90e47... Third commit
$ cat .git/HEAD
aa90e471ababde242281c833fffea255f69dd28a
$ git checkout develop
Previous HEAD position was aa90e47... Third commit
Switched to branch 'develop'Tras este mareo, este es la instantánea de nuestro histórico:
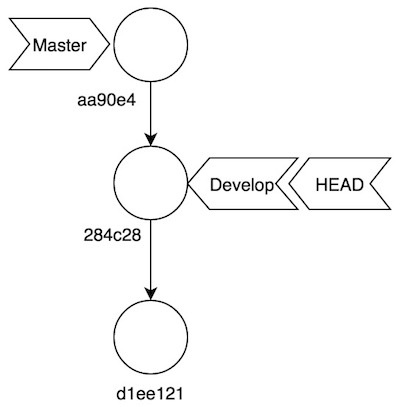
Lo dejamos aquí por hoy. En el último post de la serie veremos cómo funcionan merge y rebase, y finalizaremos con la sincronización con repositorios remotos.
| Serie completa: | Parte 1 | Parte 2 | Parte 3 | Parte 4 |