Cómo funciona Git (parte 3)
Continuamos con nuestra serie sobre el funcionamiento interno de Git. En el anterior post dejamos nuestro repositorio en el siguiente estado:
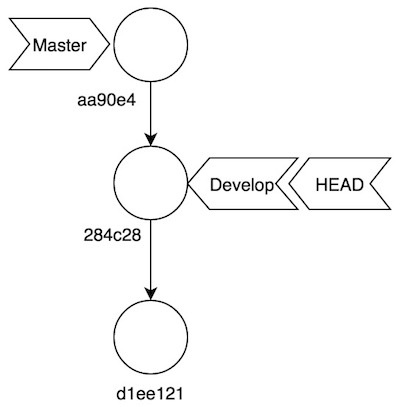
Es hora de revisar como funcionan dos de los comandos más utilizados (y más temidos también): merge y rebase.
Merge
Git merge significa algo así como “fusiona los contenidos de ambas ramas, utilizando la mejor estrategia posible, y añadiendo un nuevo commit en caso necesario”. No pretendo entrar en detalles de todas las estrategias que se pueden utilizar, tan sólo cubriré los casos más frecuentes.
Fast-forward
Veamos que ocurre si queremos fusionar las dos ramas en el estado que tenemos ahora mismo:
$ git branch
develop
* master
$ git merge develop
Already up-to-date.
$ git checkout develop
Switched to branch 'develop'
$ git merge master
Updating 284c288..aa90e47
Fast-forward
goodbye.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 goodbye.txt- Intentamos fusionar
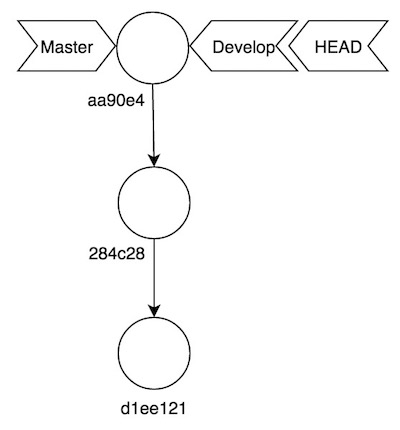
developenmaster, pero Git nos dice que la ramamasterya está actualizada. Esto es así porque la historia enmasterva por delante de la historia endevelop, siendo el último commit enmasterun sucesor del último commit endevelop. Es decir, no hay nada que hacer, porque evidentemente Git no va a eliminar nuevos commits demasterpara fusionarla condevelop. - Nos vamos a
developy la fusionamos conmaster. Vemos que Git ejecuta la tarea utilizando la estrategia “fast-forward”. Esto significa que Git ha detectado que la historia demasterque no está endeveloptiene como ancestro el último commit dedevelop, por lo que solamente necesita mover el puntero de la rama (arrastrando HEAD con él) hasta el último commit demaster. Tras realizar esta acción el contenido de Git queda así:
Recursive
Para explicar correctamente la siguiente estrategia de merge volvamos a la versión anterior de nuestro repositorio, es decir:
Es interesante recordar lo que tenemos en ambas ramas también:
$ git branch
develop
* master
$ tree
.
├── goodbye.txt
├── greetings
│ └── hello2.txt
└── hello.txt
1 directory, 3 files
$ git checkout develop
Switched to branch 'develop'
$ tree
.
├── greetings
│ └── hello2.txt
└── hello.txt
1 directory, 2 filesSiendo breves, en master tenemos un commit que añade el fichero goodbye.txt, commit que no tenemos en develop. Vamos a añadir un nuevo commit en la rama develop:
$ echo "Greeting develop" > goodbye_develop.txt
$ git add .
$ git commit -m "New commit in develop"
[develop ac88e5b] New commit in develop
1 file changed, 1 insertion(+)
create mode 100644 goodbye_develop.txtTras este commmit se nos queda el siguiente dibujo:
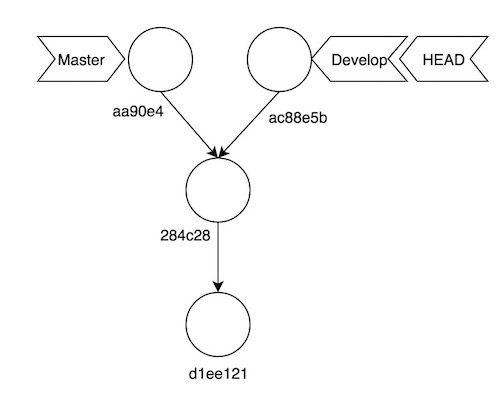
Como veis, ambas ramas han “divergido”, partiendo de un ancestro común (el commit 284c28). Vamos a hacer merge de la rama master dentro de develop:
$ git merge master
Merge made by the 'recursive' strategy.
goodbye.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 goodbye.txtGit ha utilizado la estrategia “recursive”. Esta es la historia que ha quedado en develop:
* 01c72ea 2017-03-11 | Merge branch 'master' into develop (HEAD -> develop) [RaulAvila]
|\
| * aa90e47 2017-02-11 | Third commit (master) [RaulAvila]
* | ac88e5b 2017-03-11 | New commit in develop [RaulAvila]
|/
* 284c288 2017-02-11 | Second commit [RaulAvila]
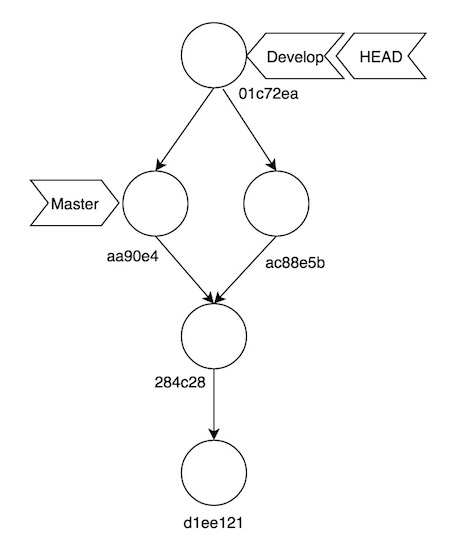
* d1ee121 2017-01-22 | First commit (tag: first) [RaulAvila]Si os fijáis bien, se ha añadido un nuevo commit del tipo “merge commit”. La gran diferencia entre un commit normal y uno de tipo “merge”, es que en este último existen dos ancestros, cosa que podemos ver fácilmente con el comando cat-file:
$ git cat-file -p 01c72ea
tree 77f9b4b34bc364b29ac12fec827985384d469ddd
parent ac88e5b089928490ff498f63218687ded7b57c87
parent aa90e471ababde242281c833fffea255f69dd28a
author RaulAvila <xxxxxx@gmail.com> 1489226224 +0000
committer RaulAvila <xxxxxx@gmail.com> 1489226224 +0000
Merge branch 'master' into developAsí nos queda nuestro “árbol” de Git, tras esta operación:
La rama master no sabe nada de lo que ha ocurrido en develop. En teoría podríamos continuar añadiendo nuevos commits en master y hacerla evolucionar de manera independiente. Pero en proyectos reales, lo más normal en estos casos es sincronizar ambas ramas, lo que en este caso es tan sencillo como hacer:
$ git checkout master
Switched to branch 'master'
$ git merge develop
Updating aa90e47..01c72ea
Fast-forward
goodbye_develop.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 goodbye_develop.txtEspero que tenga sentido lo que ha ocurrido ahora, Git ha detectado el merge que tuvo lugar en develop, por lo que para fusionar develop en master le basta con hacer un fast-forward, moviendo el puntero de la rama al “merge commit”, es decir:
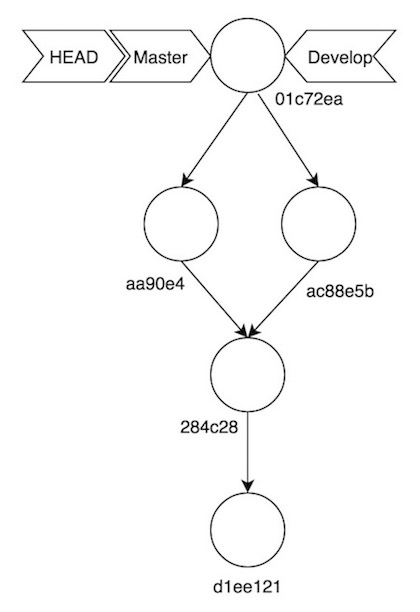
Por cierto, tras todo este proceso, nuestro repositorio ha quedado tal que así:
$ tree
.
├── goodbye.txt
├── goodbye_develop.txt
├── greetings
│ └── hello2.txt
└── hello.txtRebase
Git rebase es uno de los comandos más potentes de Git, pero también el más peligroso. No es más que una forma diferente de fusionar el contenido de dos ramas, siguiendo una estrategia bastante agresiva: reescribir la historia, sin añadir ningún commit adicional, como sí hacía merge. El mejor articulo para entender las diferencias entre merge y rebase es este, no es mi intención cubrir con mucho detalle algo que ya se ha discutido hasta la saciedad, sino mostrar cuál es el proceso interno en el repositorio de Git.
Veamos pues qué ocurre cuando hacemos rebase, y para ello partiremos de este estado anterior:
$ git branch
* develop
master
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: New commit in developLeemos dos mensajes:
- “Rewinding head to replay your work on top of it”: Git busca el ancestro común de ambas ramas (el commit
284c28), y mueve el punteroHEADpor la historia demasterhasta el último commit que encuentre allí (que esaa90e4). - “Appying: New commit in develop”: Git comienza a leer la historia de
developa partir del ancestro común (recordemos,284c28), y commit a commit, lee el contenido de cada uno de ellos (los commits pueden contener trees, blobs… leed la primera parte de la serie si no sabéis a qué me refiero), y genera, para cada commit, un nuevo commit con exactamente el mismo contenido, pero con un ancestro diferente, puesto que los va situando encima del todo en la historia, tras el último commit demaster. Recordemos que los commits en Git son inmutables, por lo que si cambia el ancestro, aún manteniendo el contenido, hay que generar un nuevo commit. En realidad no sólo cambia el ancestro, también la fecha, que contendrá el día y hora en que ejecutamos el rebase.
Como sólo tenemos un commit en develop que no esté en master, Git generará un nuevo commit con el mismo contenido, pero teniendo como ancestro a aa90e4 (el último commit de master). Este nuevo commit tendrá un hash diferente, ya que su fecha/hora y ancestro han cambiado, aún compartiendo contenido (en el caso que nos ocupa, el nuevo hash es 3e7eed). Si hubiera más de un commit en develop se seguiría reescribiendo la historia, de forma que un segundo commit se añadiría encima de 3e7eed, y así sucesivamente.
Nuestro árbol de Git queda así:
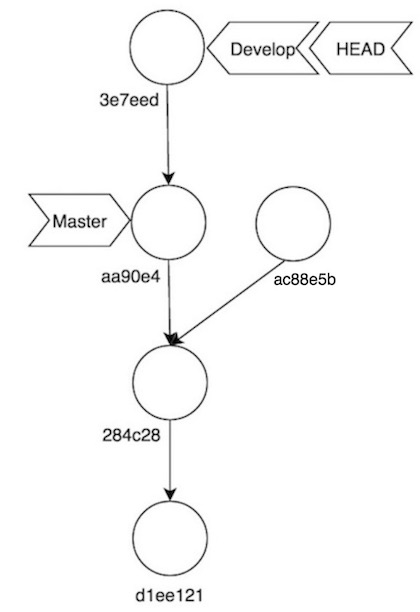
No he dejado el commit ac88e5b por error. Este es el commit que anteriormente pertenecia a develop, pero ha dejado de hacerlo tras el rebase, momento en que ha sido reemplazado por 3e7eed, que tiene el mismo contenido pero distinto ancestro. El hecho de que tengamos un commit sin ninguna rama que lo referencia significa que en algún momento el recolector de basura de Git lo eliminará de su base de datos. Pero si no queremos que eso ocurra siempre podemos crear una rama apuntando a él, recordad que una rama no es más que un puntero a un commit. Es decir, podríamos hacer esto:
$ git checkout ac88e5b
Note: checking out 'ac88e5b'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at ac88e5b... Second commit
$ git checkout -b backup
Switched to a new branch 'backup'Y desde ahora siempre tendremos una referencia a nuestra rama develop antes del rebase. De hecho conozco a gente que antes de hacer un rebase se crea una rama backup de esta forma desde la propia develop, de forma que si el rebase fracasa estrepitosamente siempre se mantiene la referencia del punto de partida:
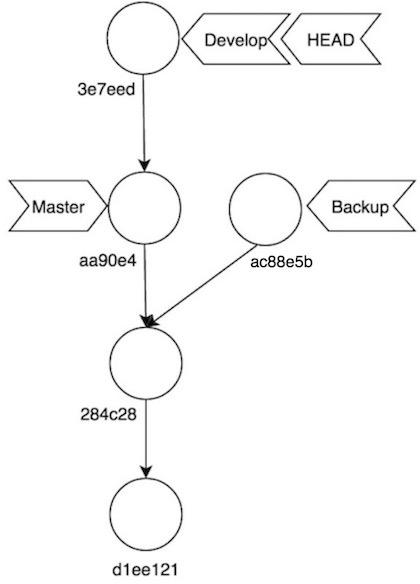
En este punto supongo que sabríais decirme lo que ocurriría si nos vamos a master y hacemos git merge develop, ¿verdad?:
$ git merge develop
Updating aa90e47..3e7eed9
Fast-forward
goodbye_develop.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 goodbye_develop.txtEn efecto, mediante un sencillo fast-forward, el puntero de master se mueve al mismo commit que completa la rama develop.
Resolución de conflictos
En la práctica, hacer merge y rebase no es tan bonito ni sencillo como acabo de representar, y normalmente tendremos que resolver los temidos conflictos. No voy a entrar en detalles sobre este tema, no es el objetivo de estos posts, tan solo añadir un par de puntualizaciones:
- Si el conflicto ocurre durante un merge donde se está aplicando la estrategia “recursive”, lo que ocurre al resolver los conflictos es que los cambios que generemos al resolverlos se añadirán al contenido (“blob”) del merge commit.
- Si el conflicto ocurre durante un rebase, Git se quejará mientras aplica uno de los commits según va reescribiendo la historia, y parará de reescribir hasta que lo arreglemos. Una vez solucionado, y tras continuar con el rebase (
git rebase --continue) los cambios se añadirán al contenido del commit que se estaba reescribiendo, por lo que en este caso se dará la situación de que un commit “reescrito” no tiene el mismo contenido que el original.
Repito, esta explicación es muy “a grosso”, y entrar en detalles requeriría un artículo en condiciones.
Finalizo aquí este post de la serie. Mi intención inicial era cubrir la forma en que Git trabaja con repositorios remotos, pero creo que desembocaría en un artículo demasiado largo y poco cohesionado. Así que lo haré en el siguiente, y ahora sí, último post de la serie.
| Serie completa: | Parte 1 | Parte 2 | Parte 3 | Parte 4 |