Cómo funciona Git (y 4)
Tenía pendiente escribir la última parte de esta serie desde hace tiempo. Tras revisar cómo Git gestiona merge y rebase, queda por ver la forma en que Git gestiona la capa de distribución, es decir, el trabajo y sincronización con repositorios remotos.
Como ya sabemos, Git es un sistema de control distribuido de versiones, donde cada persona no tiene más que una copia completa del repositorio. Es decir, cada usuario que clone un repositorio Git tendrá una copia de la carpeta .git, carpeta que contiene montones de cosas, según vimos en anteriores posts de la serie.
Normalmente el repositorio que sirve de referencia para todos los usuarios estará alojado en algún sistema como GitHub, BitBucket o GitLab, de forma que cuando queremos empezar a trabajar con un proyecto haremos un git clone de ese repositorio “remoto”. Será con esta versión “de referencia” con la que nosotros sincronizaremos nuestros cambios.
Internamente, Git almacena cierta información relacionada con este repositorio remoto en el fichero .git/config. Veamos, por ejemplo, lo que este fichero contiene para el caso del repositorio donde alojo el código de este blog:
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "origin"]
url = https://github.com/raulavila/blog-source-code.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/masterLas dos secciones importantes son las últimas, el core existirá incluso tras crear un repositorio Git local sin llegar a sincronizarlo con un remoto. Como véis, define ciertas características de donde está alojado origin, que es el nombre por defecto que Git asocia al repositorio remoto principal (ahora volvemos a esto). También vemos información que mapea nuestra rama master con el repositorio remoto origin.
Git permite asociar varios repositorios remotos a un repositorio local, tal y como está descrito aquí, aunque no es algo que recomiende especialmente. Cada uno de los remotos deberá tener un alias designado, siendo origin el primer alias por defecto que utiliza Git.
Sigamos. Recordemos que los objetos de Git en general, y los commits en particular, son inmutables. Y lo son tanto en local como en remoto, por tanto (y me estoy repitiendo), clonar un repositorio se trae a local una copia de todos estos commits. Lo que no es inmutable en absoluto es una rama (un puntero a un commmit, a fin de cuentas), y aquí es donde entra en juego la capa de distribución de Git.
En efecto, lo que ocurre en nuestro repositorio local es que Git crea dos copias de la rama en cuestion, una versión local y una remota. Supongamos que estamos trabajando con master, tras hacer Git clone de un repositorio con una historia en dicha rama, lo que tenemos es:
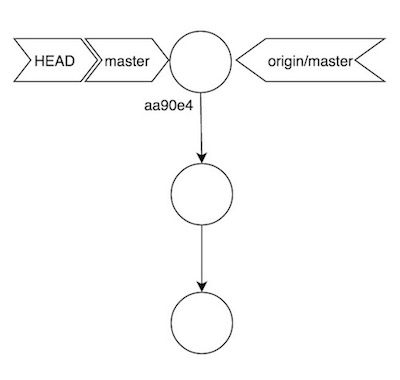
Es decir, existe una rama llamada origin/master, apuntando al último commit del repositorio remoto, que en este caso es el mismo que tenemos en local. La información de esta rama origin/master está contenida en el fichero .git/refs/remotes/origin/master:
$ cat .git/refs/remotes/origin/master
aa90e471ababde242281c833fffea255f69dd28a
$ git show-ref master
aa90e471ababde242281c833fffea255f69dd28a refs/heads/master
aa90e471ababde242281c833fffea255f69dd28a refs/remotes/origin/master
$ cat .git/HEAD
ref: refs/heads/master
$ cat .git/refs/heads/master
aa90e471ababde242281c833fffea255f69dd28aEl comando show-ref <rama> nos muestra información del commit al que apunta la rama en cuestión tanto en local como en remoto. El resto de comandos del ejemplo creo que deberían estar claros a estas alturas si habéis seguido esta serie.
Sincronizando con el repositorio remoto
Los “problemillas” en Git suelen surgir de vez en cuando a la hora de sincronizar nuestro repositorio local con el remoto. Durante el resto del post vamos a revisar diferentes escenarios.
Escenario 1
Ocurre cuando somos los únicos trabajando en master:
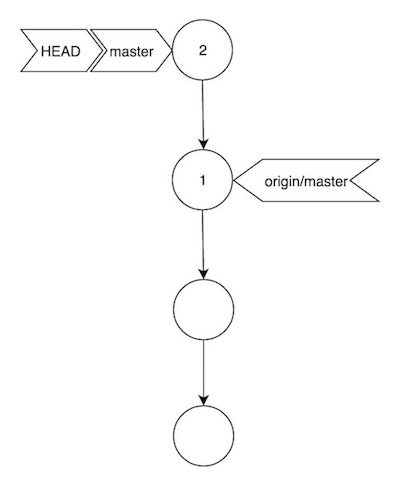
Vemos en la imagen como hemos añadido un nuevo commit (2), que ha hecho moverse los punteros HEAD y master, pero no el puntero origin/master. Esto es así porque en el repositorio remoto, la rama master sigue exactamente igual. En este escenario, sincronizar ambos repositorios es tan sencillo como hacer git push, y nuestro repositorio quedará así:
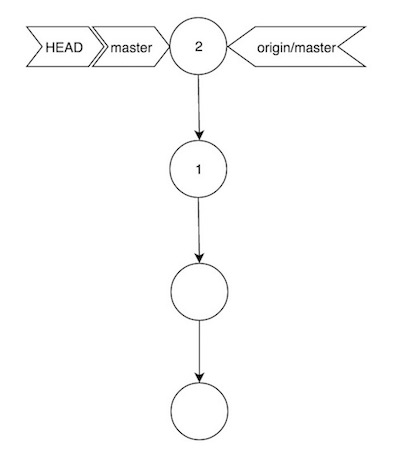
Si cualquier otro usuario trabajando con este repositorio, pero sin haber hecho ningún commit adicional en master, hiciera git pull, Git resolvería la situación fácilmente, desembocando en el mismo diagrama. Los problemillas empiezan a surgir cuando ese segundo usuario sí ha hecho algún que otro commit.
Escenario 2
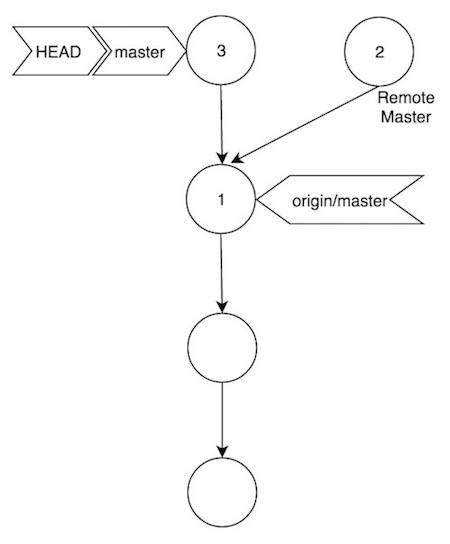
Espero que el diagrama esté más o menos claro. En este escenario, un segundo usuario ha hecho un commit (3) en su rama master local, y la rama master remota ya contiene el commit (2) que el usuario anterior incluyó en su push. Pero, para ese segundo usuario (el que tiene el commit (3)), su puntero origin/master no ha cambiado, ya que no hemos sincronizado, de forma que si intentamos hacer git push, Git detectará que la rama master remota no está sincronizada con nuestra rama origin/master local, y nos dará un conflicto / error:
$ git push
To github.com:raulavila/dummy.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'git@github.com:raulavila/dummy.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.Ante esta situación podemos optar por la solución bestia, que es invocar el comando git push -f (force push). Con esto estaremos indicando a Git que nuestra rama master es la buena, y que sobrescriba toda la historia de master en origin para que coincida con la copia en local. Como os podéis imaginar, esto es muy, muy peligroso. Personalmente, la única situación en la que he encontrado una buena justificación para hacerlo es cuando yo soy la única persona trabajando en una rama diferente de master, pero en la que llevo a cabo rebases de master con frecuencia. Al hacer rebase reescribo la historia de mi rama, y si hago push a la remota, habrá divergencias todo el tiempo. Pero al ser yo la única persona que trabaja en esa rama, sé con seguridad que no hay problema en forzar un push.
Una estrategia más segura, es hacerlo en dos pasos:
1 - Invocar el comando git-fetch, que sincroniza los contenidos de las ramas origin/* en local, sin llevárselos a las versiones locales. Lo sé, es confuso, pero espero que lo entendáis mejor con el diagrama:
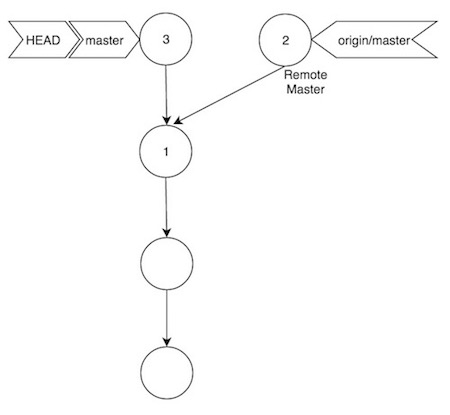
Fijaos en que origin/master, ha pasado del commit (1) al (2), es decir, nuestro Git local ya está al tanto de los nuevos cambios en remoto. Viendo la salida de show-ref, podemos ver cómo los commits de master y origin/master son diferentes:
$ git show-ref master
9232aacf90cd50182e7608b5b051250c97ab109d refs/heads/master
0e0a1c2800d295e25b7766a8b66fc681be3a2f07 refs/remotes/origin/master2 - Hacer un merge de las ramas master y origin/master (git merge origin/master):
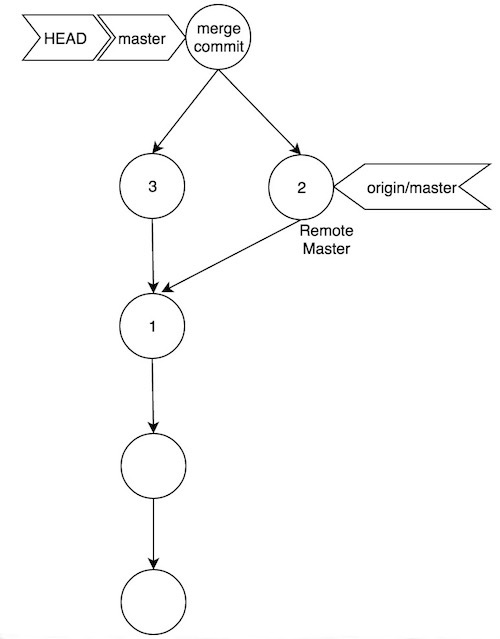
Vemos que ahora hemos resuelto el problema, ya que el “merge commit” tiene como padre el último commit en la rama remota master. Por lo que si nadie ha añadido nuevos commmits en dicha rama, ahora sí, podremos hacer git push sin problemas.
En realidad, estas dos acciones pueden llevarse a cabo de una, con el comando git pull, que seguro todos conocéis. En su versión por defecto, este comando no hace más que un fetch + merge, de la forma en que hemos visto.
Si recordáis el anterior artículo, podemos utilizar rebase como alternativa a merge para fusionar ramas. Esto tiene ventajas y desventajas, no olvidéis que vamos a reescribir la historia, pero en el caso de que vayamos añadiendo sucesivos commits en nuestra versión local, antes de hacer push me parece una buena práctica hacer un rebase de la master remota en lugar del merge que hemos visto. Así conseguiremos una historia más limpia, sin merge commits innecesarios y sin ramas cruzándose.
Para conseguir esto, aunque es posible hacer fetch + rebase, la forma rápida es mediante el comando git pull --rebase. En nuestro ejemplo, si hiciéramos esto en lugar de pull sin más, la foto final quedaría así:
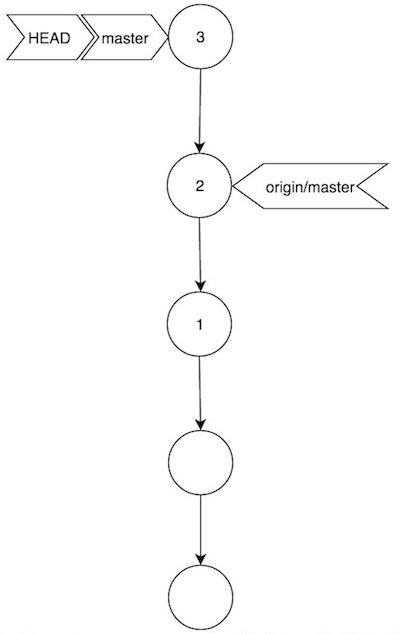
Siendo ahora el commit (2) exactamente el mismo que existe en el master remoto, y (3) una reescritura llevada a cabo durante la operación de rebase. Para terminar, sería necesario sincronizarlo todo con git push:
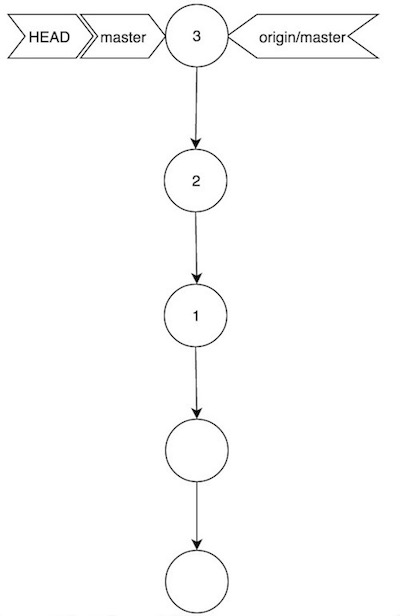
Escenario 3: lo mismo, pero con conflictos
Si surgen conflictos durante las operaciones de merge o rebase, no hay ninguna diferencia entre el proceso que se lleva a cabo para solucionarlos durante una sincronización con el repositorio remoto respecto a lo que ocurre durante una fusión entre ramas. Por tanto, os remito de nuevo a la breve descripción al respecto que aparecía en el anterior post de la serie.
Conclusiones
Espero que esta seria os haya servido de ayuda para perder el miedo a Git. Personalmente, conocer todos estos detalles sobre el funcionamiento de la herramienta ha conseguido que cuando surge un conflicto no pierda los nervios de forma inmediata, como sí me ocurría antaño :).
| Serie completa: | Parte 1 | Parte 2 | Parte 3 | Parte 4 |